1-Contexte 2-Objectifs 3-Approche 4-Limitations 5-Amťliorations 6-ParamŤtres Matlab
1-Contexte
 |
| Pas toujours idťal! |
L'article en question peut Ítre retrouvť ICI !.
2-Objectifs
Les objectifs du projet de stabilisation de vidťo sont somme toute assez simples ŗ expliquer, mais beaucoup plus durs ŗ implťmenter. Il faut au final, recrťer une vidťo plus stable que l'originale en minimisant les accťlťrations soudaines et autres distorsions. Le rendu final doit avoir l'allure d'un film tournť ŗ l'aide d'un chariot et d'une camťra stable comme on le fait au cinťma. L'algorithme doit pouvoir Ítre utilisť aprŤs que la vidťo soit tournťe, on ne fait donc par de traitement en direct (live), mais bien du ępost-process video stabilizationĽ. Finalement on peut ajouter quelques mťthodes de tracking d'objets afin de rendre l'algorithme plus stable et de bien recentrť le vidťo final, par exemple, en utilisant un dťtecteur de visage on peut s'assurer que la vidťo soit le plus possible focalisťe sur ce visage par exemple.
3-Approche
La stabilisation peut se rťsumer en 3 grandes ťtapes, soient ;
1) L'estimation de la trajectoire (possiblement instable) de la camťra (en utilisant le vidťo source)
2) L'estimation d'une nouvelle trajectoire de camťra optimale (plus stable)
3) Reconstruction d'une nouvelle vidťo en utilisant l'estimation de la trajectoire la plus stable, un tracking de zones intťressant (visage, voiture, ballon, etc.) ainsi que le
redimensionnement du vidťo (cropping)
…tape 1 - Estimation de la trajectoire initiale
 |
 |
| Dťtection | Traquage |
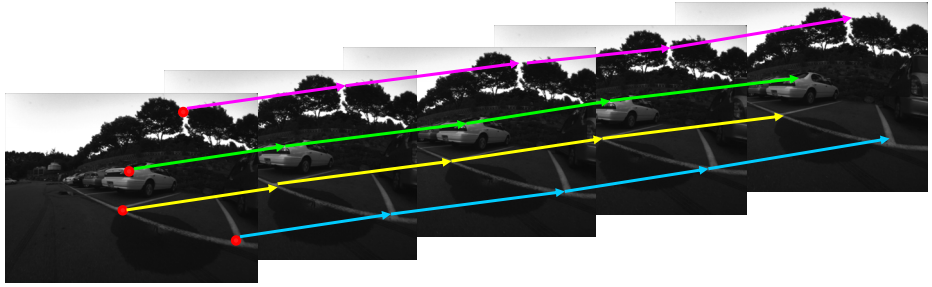
Pour effectuer l'estimation de la trajectoire prise par la camťra, l'algorithme de ętraquageĽ de points de Kanade, Lucas et Tomasi ŗ ťtť utilisť. Il est plus communťment appelť Kanade-Lucas-Tomasi (KLT) feature tracker. L'utilisation de cet algorithme permet de dťterminer pour des points d'intťrÍts P1(x,y) d'une image I1, les points d'intťrÍt P2(x,y) correspondants dans une image I2 (dans ce cas, l'image suivante dans le vidťo). On aura donc des paires de correspondances que l'algorithme pourra traquer sur toutes les images.
On doit d'abord dťterminer des points d'intťrÍts dans l'image initiale et leur choix est important, car en choisissant mal ceux-ci, les rťsultats peuvent Ítre plus ou moins bons. En effet, il est difficile de faire la correspondance d'un pixel noir parmi un arriŤre-plan noir donc, il faut utiliser des points qui sont plus facilement discernables. Pour ce faire, il existe de nombreux algorithmes de dťtection de points importants (tels des coins, des variations de couleurs importantes, gradient ťlevť, etc.), mais chacun d'eux fourni des rťsultats diffťrents qui font en sorte que les rendus finaux sont meilleurs avec certains algorithmes que d'autre. Dans le cadre de ce projet, 3 algorithmes ont ťtť testťs, soit :
 |
| Pyramide de l'algoritme KLT |
2) L'algorithme de valeurs propres minimale (Min Eigenvalue)
3) L'algorithme de dťtection de caractťrisques FAST (Feature from Accelerated Segment Test)
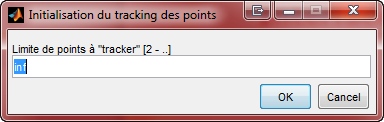
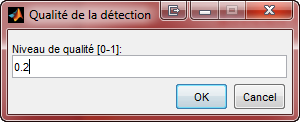
La dťtection des points doit Ítre bien fait pour de bons rťsultats, et il est une bonne chose de dťterminer la robustesse des points utilisťs (ne prendre que les meilleurs), la quantitť de ceux-ci, car s'il sont trop nombreux, cela peut ralentir quelque peu le processus de stabilisation. De plus en dťterminant une zone limite dans laquelle peuvent se trouver les points, on fait en sorte de bien faire le suivi d'un objet qui nous intťresse dans le vidťo afin de bien ajuster celui-ci avec l'objet en question.
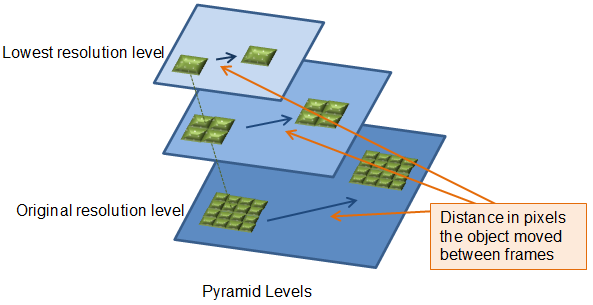
Cet algorithme est utilisť de maniŤre pyramidale, c'est-ŗ-dire, qu'on effectue le calcul du mouvement des points ŗ plusieurs ťchelles de redimensionnement d'image (de la plus petite vers la plus grande, soit l'image d'origine). Pour chaque niveaux de redimensionnement, on utilise un facteur d'ťchelle de 2 et habituellement, de 2-4 niveaux suffisent ŗ l'obtention de bons rťsultats. Il est aussi important de bien dťterminer une rťsolution (dimension) des blocs qui correspondent aux pixels entourant les points d'intťrÍt. Ces blocs doivent Ítre ni trop petits, ni trop grands.
 |
| Erreur bidirectionnelle |
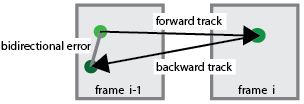
Avec ces points qui ont ťtť traquťs, il est possible, ŗ l'aide de leurs coordonnťes de trouver un systŤme d'ťquations linťaires correspondants aux mouvements des points. En effet, ŗ l'aide de ces ťquations il est aisť de retrouver les transformations qui ont permis de retrouver les diffťrents points d'intťrÍts d'une image dans une seconde image. Ces transformations affines ou projectives (incluant donc les phťnomŤnes de rotation, translation et facteur d'ťchelle) permetterons entre autres ŗ reconstituer la trajectoire optimale de la camťra. Puisque nous sommes en prťsence d'une multitude (ce n'est pas toujours le cas !!!) de points, il faut donc faire le tri des meilleures options de transformations et pour se faire, nous avons fait l'utilisation de la mťthode itťrative MSAC (M-Estimator Sample Consensus), semblable ŗ la technique dite RANSAC. Finalement, avec ces transformations dťterminťes il est possible d'approximer le mouvement de la camťra.
Afin de bien faire le suivi des points, il est impťratif de redťterminer des nouveaux points d'intťrÍts aprŤs quelques images, puisque du dťbut ŗ la fin du vidťo, les points d'intťrÍts risquent de se ęperdentĽ et nous ne voulons pas faire de la reconstitution de scŤne qui serait trop lourde et ralentirait le processus de stabilisation. On recalcule ainsi un nouveau systŤme d'ťquations linťaires et ainsi de suite.
Finalement, avec ces transformations dťterminťes il est possible d'approximer le mouvement de la camťra et d'affirmer que cet algorithme KLT robuste permet une bonne rejection des ęoutliersĽ (donnťes aberrantes) entre des paires de points et est moins dispendieux en terme de temps de calcul que l'utilisation de la technique dite ęStructure from MotionĽ.
 |
 |
| Points d'intťrÍts dťtectťs (algorithme FAST) | Dťtection de la vťlocitť des mouvements |
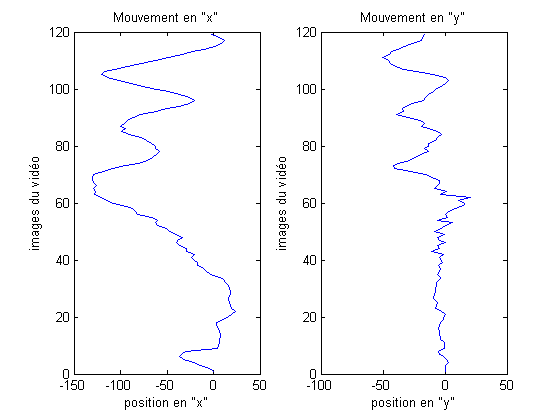 |
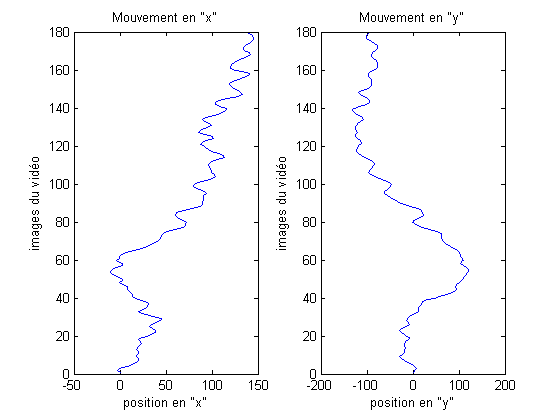 |
| Mouvement en X et Y (camťra GoPro) | Mouvement en X et Y (camťra standard) |
…tape 2 - Estimation de la trajectoire optimale
 |
| Transformation et dťcalage entre 2 images |
Afin de minimiser la transformation des images, il faut se fier aux transformations de l'image prťcťdente et suivante auquel on leur associe un poids afin de crťer un mťlange des 3 transformations. On trouve ainsi une image la moins dťformťe possible, mais qui correspond le plus ŗ l'image prťcťdente. Gťnťralement on donne un poids plus ťlevť ŗ l'image suivante qu'ŗ l'image prťcťdente.
Une autre bonne habitude est d'utiliser des points de ętrackingĽ ŗ inclure en tout temps dans le calcul (s'il sont dans l'image bien sŻr, et d'y associer une plus grande robustesse).Il existe d'autre technique ŗ employer qui permet d'obtenir de meilleurs, mais il n'ont pas toutes ťtť implťmentťes. L'algorithme du ęRobust Optimal L1 PathĽ et toutes ses subtilitťs est bien dťcrit dans l'article dont ce projet est basť.
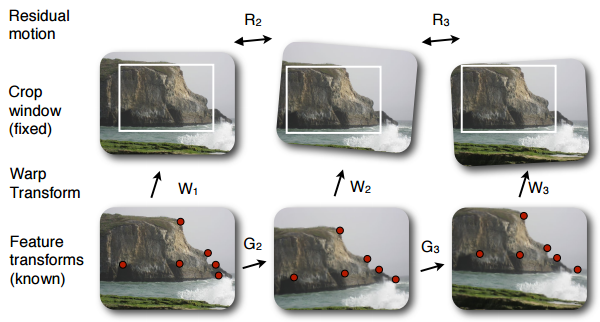 |
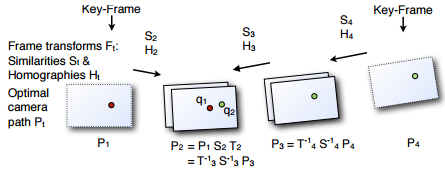 |
| Estimation trajectoire optimale | Transformations entre les images |
Ici, on ŗ donc nos systŤmes d'ťquations linťaires (G), nos transformations (W) et les diffťrences/dťcalage (R) entres les images transformťes.
…tape 3 - Reconstitution du vidťo
Pour reconstruire le vidťo, on effectue un recadrage des images qui correspondent ŗ la trajectoire optimale. Le recadrage doit faire en sorte de conserver la plus grande portion d'image possible comme nous n'utiliserons pas de reconstruction d'images. On dťtermine donc la plus grande fenÍtre valide et il est mÍme mieux de la mettre encore plus petit bien que nous perdons ainsi de l'information, mais on gagne en stabilitť d'image.
 |
 |
 |
| Mouvement moyen (sur 120 images) | Mouvement moyen CORRIG… (sur 120 images) | FenÍtrage optimal |
 |
 |
| Mouvement moyen (sur 180 images) | Mouvement moyen CORRIG… (sur 180 images) |
Comme on peut le remarquer, pour le vidťo sur 180 prises avec une camťra standard (clip provenant de ce VIDEO!), il est difficile de dťterminer un trŤs bon chemin ťtant donnť que le vidťo est EXTR MEMENT instable, un peu flou et donc la dťtection et le tracking de points ŗ du mal ŗ bien performť. Si on cherche des points robustes, on en trouve pas assez et ceux disponibles ne nous donnent pas de bonnes informations. Toutefois, on peut remarquer une plus grande stabilitť de l'image avec notre algorithme. Pour les rťsultats avec la GoPro Hero4, il sont assez concluants. On remarque que mon pied ŗ bouger rapide ŗ plusieurs reprise, mais ce n'est pas cela qui rendrait le vidťo dťsagrťable, c'est plutŰt l'effet de vibration engendrť par le longboard qui crťe des distorsions de hautes et basses frťquences et qui font en sorte que le paysage semble flou. Avec notre algorithme on stabilise nettement l'image au cours du vidťo comme on peut le remarquer par les fenÍtres du b‚timent et l'automobile blanche qui semblent beaucoup plus distinctes.
4-Limitations
Voici une ťnumťration de quelques limitations de cette technique de stabilisation :
1) Ne fonctionne pas bien pour des vidťos trop flous
2) ņ du mal avec les mouvements trop brusques qui crťer des transformations trop prononcťes
3) ņ du mal ŗ bien fonctionner s'il manque d'objets distincts dans la scŤne
4) Il faut constamment gťrer la perte des points de repŤres
5-Amťliorations
Voici une ťnumťration de quelques amťliorations au projet:
1) Pousser plus loin (plus de contraintes de dťtection) l'algorithme d'optimation du chemin.
On pourrait y inclure des points fixes, un face-tracking et limitť les transformations de mise ŗ l'ťchelle, etc.
2) Faire le recadrage de maniŤre dynamique (ŗ chaque fois qu'on crťe l'image dťformťe)
3) Utiliser la reconstitution d'image pour ťviter le recadrage
4) Faire la fusion d'image avec une plus grande plage d'images
5) Avoir un rendu vidťo final :( !
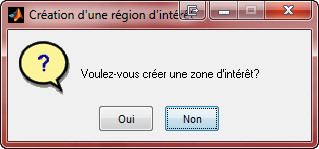
6-ParamŤtres Matlab
 |
 |
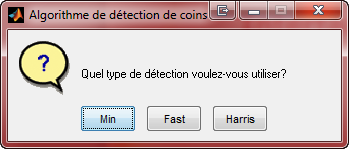 |
| Sťlection d'image | Dťtermination de zone | Algorithme ŗ utiliser |
 |
 |
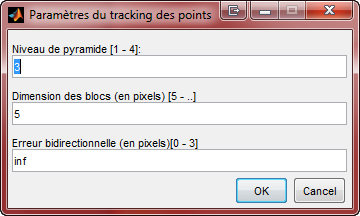 |
| Nombre de points ŗ traquer | Qualitť de dťtection | ParamŤtres de l'algorithme KLT |