Visual Hull
The Visual Hull is a 3D reconstruction of the an approximation of an object shape. This concept, first introduced by Baumgart, is strongly linked to image segmentation. The basic algorithm for Visual Hull extraction is there step process. First each input image is segmented in order to obtain a silhouette of an object. Then, using camera parameters, a silhouette of an object is projected to 3D space thereby creating a visual cone. Finally a visual hull is obtained as the intersection of all the visual cones generated for different points of view.
The advantage of this method is that it requires neither constant object appearance nor the presence of textured regions, unlike in multi-view stereo for instance. Another advantage is that it is quite simple to calculate the visual hull and it is also simple to represent it in 3D. The primary disadvantage of this approach is the inability to obtain the exact shape of the object. For instance, cavities in the object cannot be reproduced using visual hull.
Note that, in practice it is quite difficult to represent the visual hull as an intersection of visual cones, a more convenient way being to use a voxel grid. Therefore, in order to compute the visual hull, all the voxels from the voxel grid are projected onto each object silhouette, instead of back projecting each silhouette into 3D space.
A Matlab implementation of the Visual Hull extraction can be found here:
Visual Hull Matlab
or at
GitHub.
Visual Hull of a "DinoRing" and a "TempleRing" datasets from middlebury:
Unsupervised Visual Hull
As mentioned above, the Visual Hull depends entirely on the object silhouette and it is therefore independent of object appearance or presence of textured regions. This properties allows the construction of the visual hull of wide variety objects with completely different photometric properties such as textured or textureless objects, shiny or lambertian surface reflectance, opaque or transparent objects.
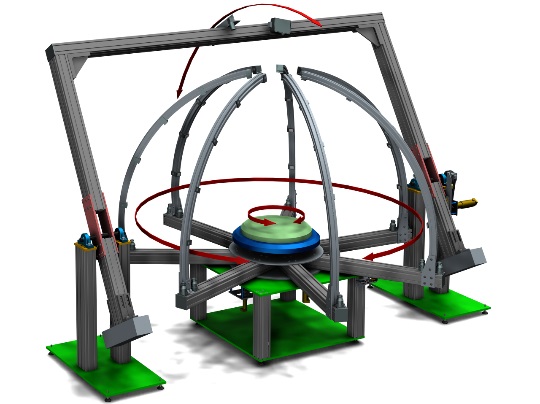
One of the key features of our work is the use of an experimental setup. This roboticized system was designed to capture a dataset from different viewpoints and under different lighting conditions. This system allows the rotation of an object on a turntable. The turntable can be rotated around the z axis by 360 degrees. The lighting system can also be rotated independently of the turntable around the z axis by 360 degrees and it is also possibility to switch on and off each light sources. The last element of the setup is a camera system, it can be rotated by 180 degrees around the x axis and thus it is possible to capture an object from any viewpoint on a hemisphere. An abstract form our latest publication available below.

This paper presents an image segmentation approach for obtaining a set of silhouettes along with the Visual Hull of an object observed from multiple viewpoints. The proposed approach can deal with mostly any type of appearance characteristics such as textured or textureless, shiny or lambertian surface reflectance, opaque or transparent objects. Compared to more classical methods for silhouette extraction from multiple views, for which certain assumptions are made on the object or the scene, on the background or the object appearance properties. In our approach, the only assumption is the constancy of the unknown background at a given camera viewpoint while the object is under motion. The principal idea of the method is the estimation of the temporal evolution of each pixel over time which leads to a robust estimation of background likelihood. Furthermore, the object is captured under different lighting conditions in order to cope with shadows. All the information from the space, time and lighting domains is merged based on a MRF framework and the constructed energy function is minimized via graph cuts.
Few results from our latest work: Visual Hull of vine glass and a light bulb.
References:
Shape from silhouette under varying lighting and multi-viewpoints
M. Mikhnevich, P. Hébert
The Conference on Computer and Robot Vision (CRV), 2011.
Unsupervised visual hull extraction in space, time and light domains
M. Mikhnevich, P. Hébert, D. Laurendeau
Computer Vision and Image Understanding (CVIU), 2012.
Shape from silhouette in space, time and light domains
M. Mikhnevich, D. Laurendeau
International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), 2014