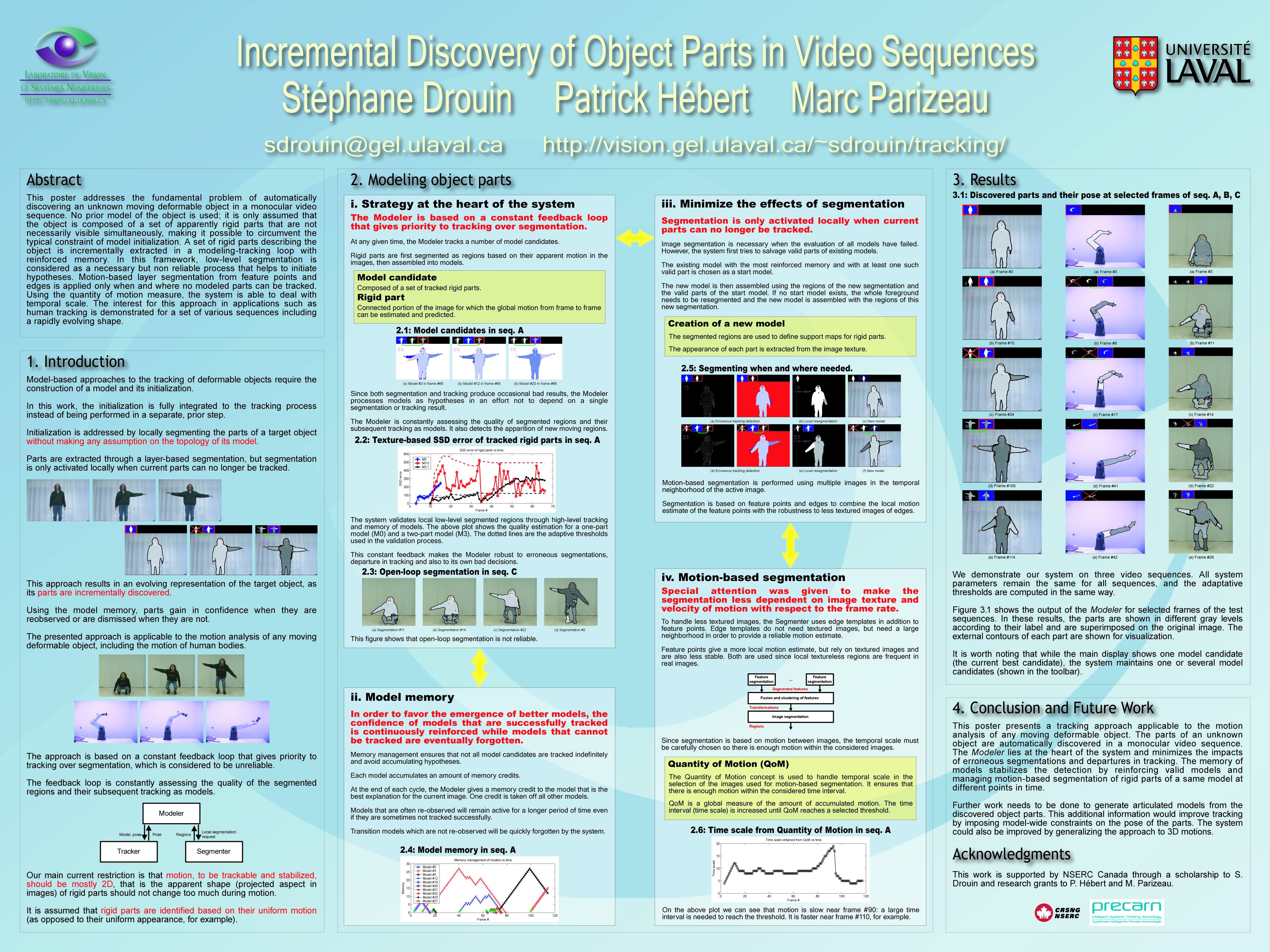
 This work addresses the problem of automatically discovering the rigid parts of an initially unknown moving deformable object in a monocular video sequence. The parts are first extracted through motion-based segmentation, using a time scale automatically chosen with the quantity of motion concept. Tracking and reobservation reinforce these low-level segmentation results and further segmentation is performed only when and where no modeled parts can be tracked. The sequential nature of the framework allows incremental modeling and segmentation of parts that need not simultaneously be visible or in motion, making it possible to circumvent the typical constraint of model initialization. The fundamental principles are strictly ensemblist and do not rely on any specific PDF. The interest of this framework is demonstrated on three types of video sequences including human and robot motion.
http://vision.gel.ulaval.ca/en/Projects/Id_225/Projet.php
This work addresses the problem of automatically discovering the rigid parts of an initially unknown moving deformable object in a monocular video sequence. The parts are first extracted through motion-based segmentation, using a time scale automatically chosen with the quantity of motion concept. Tracking and reobservation reinforce these low-level segmentation results and further segmentation is performed only when and where no modeled parts can be tracked. The sequential nature of the framework allows incremental modeling and segmentation of parts that need not simultaneously be visible or in motion, making it possible to circumvent the typical constraint of model initialization. The fundamental principles are strictly ensemblist and do not rely on any specific PDF. The interest of this framework is demonstrated on three types of video sequences including human and robot motion.
http://vision.gel.ulaval.ca/en/Projects/Id_225/Projet.php
Results - 2007 (QuickTime):
- Sequence SD: models and model evaluation vs. input images.
- Sequence SD: closed-loop modeling vs. open-loop segmentation.
- Sequence SD: models vs. model memory.
- Sequence Jeff2: estimated quantity of motion (QoM) vs. input images.
Results - 2006 (MPEG1):
- Sequence A - input, output (after reset at #118);
- Sequence B - input, output;
- Sequence C - input, output.
Results - 2005 (MPEG1):
Current research topics:
- Tracking-based discovery and validation of articulated models;
- Tracking-based occlusion handling;
- Improving segmentation results with time scale.
Publications:
Stéphane Drouin, Patrick Hébert and Marc Parizeau.
Incremental Discovery of Object Parts in Video Sequences.
To appear in Computer Vision and Image Understanding, 2007.
Stéphane Drouin, Patrick Hébert and Marc Parizeau.
Incremental Motion-Based Discovery of Object Parts in Video Sequences.
In 16th Annual Canadian Conference on Intelligent Systems (IS-2006), Victoria, B.C., May 31 - June 2 2006.
(IS2006 poster)
Stéphane Drouin, Patrick Hébert and Marc Parizeau. Incremental discovery of object parts in video sequences.
In IEEE International Conference on Computer Vision (ICCV 2005), Beijing, China, October 15-21, 2005.
(ICCV poster, PDF)
{kind=link}
{kind=link}