TP3 : Morphage de visages++
Travail pratique dans lequel on doit morphe des visages
Description du travail pratique
Dans ce rapport, on présente les résultats des deux remises.
Partie A, algorithme de morphage
Dans la partie A, on morphe progressivement des images à partir de points de référence qu'on définit nous-mêmes. On ne présente pas le vidéo pour le pas prendre trop de place dans le fichier de remise, mais celui-ci a été soumis dans la remise de la partie A.
Images de l'internet
On morphe premièrement deux boutielles de 2L de boisson gazeuse de styles différents. Les tailles de etiquettes et les formes de bouteilles ne sont pas les mêmes.



Le morphage est assez bien réussi. On remarque que pour les lignes droites, comme dans le haut des etiquettes, on remarque que la différence entre les deux images lors du morphage. Alors, il est très important de faire attention aux choix de points lorsqu'il y a une ligne droite dans les images et les traîter avec attention. Ensuite, on morphe une Beetle de VW vers une Lamborghini.



Le morphage est encore une fois bien réussi. On remarque que le haut de la roue avant droite (du point de vue de l'image) ne se morphe pas bien car les points de références sont difficiles à prendre à cette endroit et étant donné que la distance entre la roue et le par-brise est très différent dans les deux modèles de voiture.
Ensuite, inspiré de la meilleure chanson québecoise en 2018, Basilic - Qualité Motel, je morphe du romarin vers du basilic. Dans cette chanson, on peut entendre Curieux Bégin dire "J'en metterais dans mon bain", "As-tu déjà vu ça du romarin anti-oxident, ben non ça s'peut pas c'est juste le basilic qui fait ça" et "le romarin s'tu bon contre les piqures de scorpion ? Non, pentoute, le romarin s'pas bon pour ça". Comme le refrain le dit, "s'pas du romarin, c'est du basilic" et ce n'est effectivement pas du romarin.



Bien que les formes sont très différentes (de bâtonnets vers des feuilles), le morphage est lisse avec seulement 16 points. Pour un meilleur résultat, j'aurais pu mettre 3 références sur chaque piques de romarin vers chaque feuilles de basilic mais cette tâche aurait été laborieuse.
Images personnelles
En manque d'inspiration et en manque de temps, j'ai morphé les choses que j'ai trouvé le plus proche de mon bureau.



Le morphage des couteaux sont très bons car les points de références sont similaires et la forme des objets sont similaires. De plus, même si la photo n'a pas été prise exactement à la même place, le morphage est assez lent pour pas que les changements dans le patron du bureau soit évident.



Les souliers sont de styles différents. Ainsi, le morphage du contour des souliers est lisse car les points de références sont simples à identifier. Par contre, vu qu'un soulier a des lacets et que l'autre non, cette partie du morphage n'est pas aussi bonne, surtout pour le morceau du lacet qui dépasse le plancer.


Ensuite, pour éviter de simplement faire du morphage d'un objet à un autre mais du même style, j'ai décidé de morpher deux objets complètement différents. Je morphe du soulier 2 de l'exemple précédent vers mon agrapheuse. Encore une fois, le morphage du contour de l'objet est bien fait car les points de références sont faciles à identifier. Par contre, l'intérieur est moins lisse. On peut voir mes initiales sur l'agrafe pour pas que je me la fasse voler. Cette étiquette n'a pas vraiment de repère correspondant sur mon soulier alors le coin droit en bas apparaît à une place bizzare. Ensuite, on peut remarquer qu'il y a une discontinuité sur le bout du soulier à la gauche (il faut zoomer beaucoup). Ceci est dû au point de référence sur le papier collan qui est très proche du bout du soulier, alors le point moyen entre l'agrafeuse et le soulier est très proche et on obtient une triangulation qui produit cette discontinuité.
Points supplémentaires : morphage hybride (10%)
On morphe une image après un filtre passe-bas et un filtre passe-haut.



Même si les images ne sont pas très similaires, le morphage se fait assez bien car les filtres hauts apparaissent lentement et les filtres bas disparaissent lentement. Alors, aucun attribut du même filtre n'est échangé et on ne peut pas les remarquer.
Points supplémentaires : coordonnées polaires (10%)
J'essaie de morpher les images dans un autre système de coordonnées, dans ce cas-ci polaire. Par contre, je rencontre quelques problèmes. On projète les coordonnées $x, y$ vers $\rho, \theta$ selon les équations suivantes : $$\rho = \sqrt{x^2 + y^2};$$ $$\theta = \mathrm{atan} 2(x, y),$$ voir wikipedia pour les détails. Premièrement, la matrice $T$ dans un système de coordonnées homogènes est habituellement de la forme $$\left[ \begin{array}{ccc} a & b & c \\ d & e & f \\ 0 & 0 & 1 \end{array} \right].$$
Voici une image projetée en coordonnées polaires ainsi que sa triangulation:
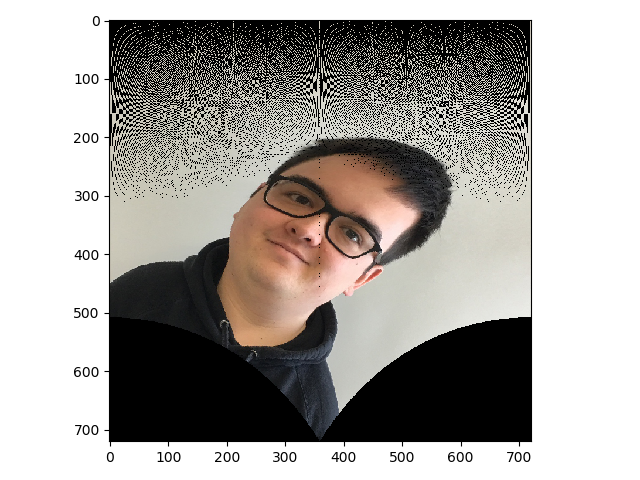
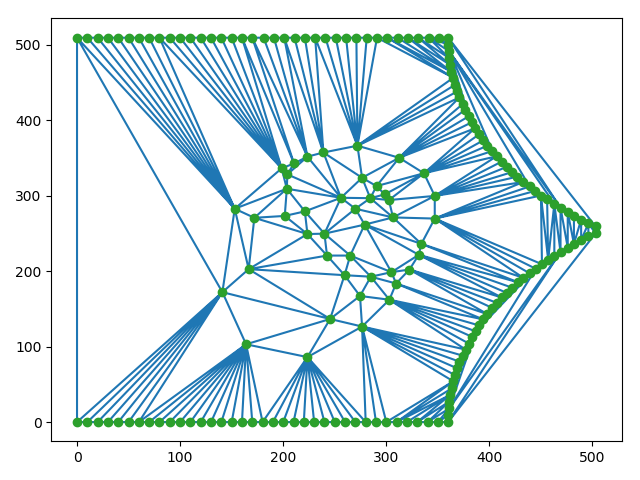
On remarque premièrement que l'image est trouée même avec de l'interpolation. Entre autre, pour des valeurs de $\theta$ basses (0 dans l'axe des $y$). De plus, le triangle de Delaunay produit des triangles hors de l'image d'origine. Ensuite, la matrice $T$ obtenue est plutôt de la forme
$$\left[ \begin{array}{ccc} a & b & c \\ d & e & f \\ 0 & 0 & 0 \end{array} \right].$$Ceci fait du sens, car il n'y a pas de translation dans les coordonnées polaires. L'origine est toujours à la même place (angle = 0 et rayon = 0). Alors, on travaille seulement avec une matrice de transformation linéaire de la forme
$$\left[ \begin{array}{cc} a & b \\ c & d \end{array} \right].$$On note qu'on doit absolument retirer la troisième dimension car sinon, les projections deviennent vont chercher des pixels négaties. Ensuite, on reprojète vers le système de coordonnées cartésien selon
$$x = \rho \cos (\phi);$$ $$y = \rho \sin (\phi).$$


On remarque une grande perte d'information. De plus, le morphage n'est pas bien fait. Alors, on devrait probablement trouver un algorithme complètement différent pour effectuer cette tâche.
Partie B
Pour cette partie, je prends les points landmark calculés par le merveilleux auxiliaire pour le cours.
Par contre, une version du code pour générer les points à partir de dlib est disponible dans
partieb/utils/get_pts_from_images.py. Il y a une différence de $\pm 1$ pour les images landmark mais
je prends mon code seulement quand je dois annoter des nouvelles images.
1. Calcul du visage moyen
Dans cette section, on calcule le visage moyen de la classe et de la base de données Utrecht. Le code est fourni
dans partieb/main_morph_images.py. La fonction calculate_mean_points calcule la moyenne
des points de référence, la fonction add_contour_points ajoute des points de référence autour de
l'image et la fonction morph_to_tri morphe l'image de départ vers une triangulation de Delaunay.
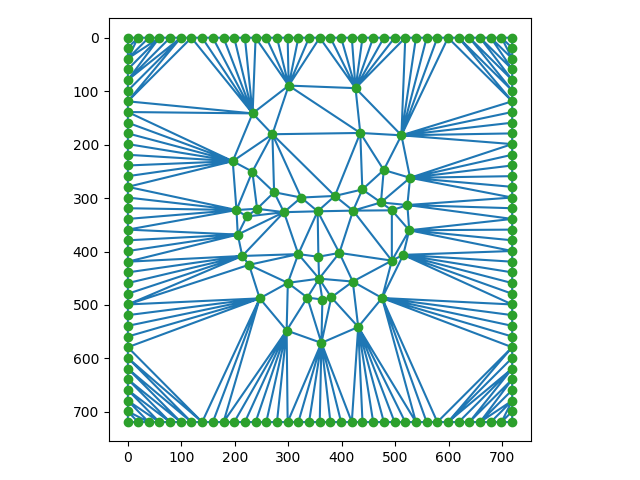
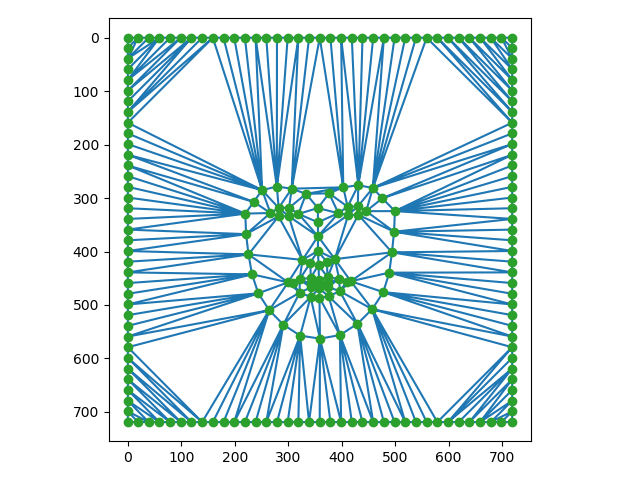
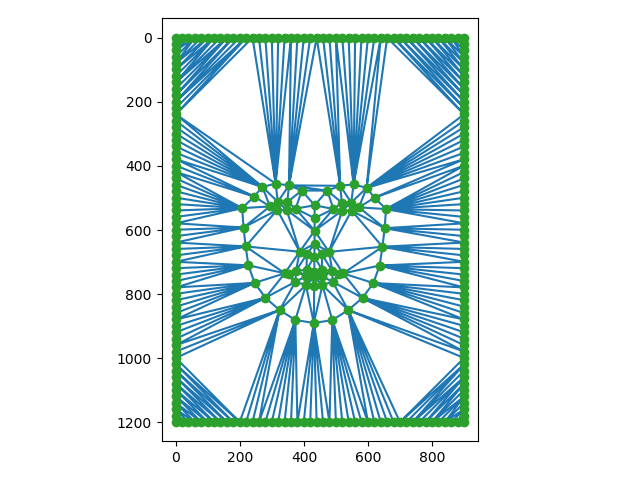
On remarque que les points sélectionnés par la classe ne sont pas les mêmes, alors les triangles sont très
différents. En effet, dlib sélectionne des attributs dans le visage alors que les points sélectionnés
par la classe passaient aussi autour de la tête. On présente maintenant les images moyens avec les projections.
On remarque aussi que les points moyens avec dlib sont similaires : c'est possiblement parce que la
personne moyenne a une forme similaire dans les deux jeux de données, ou l'algorithme produit toujours des résultats
silimaires.



On remarque que l'image moyen généré par les points sélectionnés par la classe ont des plus hautes fréquences,
en moyenne, que les points générés par dlib car le contour du visage a aussi été sélectionné.
Ainsi, les cheveux et les oreilles sont moins flous avec les points sélectionnés à la main. Par
contre, l'aire où les points de dlib sont sélectionnés produit des fréquences plus basses et les
charactéristiques sont moins flou. Par contre, laisser des utilisateurs soumettre des données peut être dangereux.
En effet, un étudiant n'a pas envoyé le bon format des données et a inversé les colonnes $x$ et $y$. Alors, son
image apparaît de côté dans le calcul de l'image moyen. Finalement, ni les points sélectionnés à la main ou les
points identifiés par dlib peuvent identifier les lunettes. Alors, les lunettes n'ont souvent pas la
même forme et l'alignement des lunettes n'est pas très bonne dans les images moyens.
Crédits supplémentaires : Sourires d'Utrecht (5%)
Les images où les sujets sourient ont un code d'image qui termine par un s. Alors, on peut
facilement calculer le visage moyen pour les sujets qui sourient et ceux qui ne sourient pas pour avoir une
meilleure correspondance autour du visage.



On présente le visage moyen avec sourire, le visage moyen sans sourire, et un gif qui présente sans, les deux, et avec sourire pour aider à voir les différences. On remarque l'image moyen de sujets qui sourient a un sourire et le visage moyen des sujets qui ne sourient pas n'a pas de sourire. On remarque aussi qu'un peu de dents apparaîssent pour les images avec sourire, ce qu'on ne voyait pas dans les autres images. Quand les sujets sourissent, leurs yeux sont aussi plissés et leur visage lève, comme on peut le voir avec la baisse du coup et des gilets.
2. Masculinisation et féminisation de mon visage
Je présente premièrement les images des visages masculins et féminins moyens. Le morphage des visages est fait
dans le fichier partieb/main_sex.py et l'image moyen est créé dans le fichier
partieb/main_mean_image.py


On note qu'il y a 92 images d'hommes et 39 images de femmes. Alors, l'image moyen ressemble à l'image moyen des sujets masculins. Ensuite, je projète mon image vers la forme moyenne pour un homme et la forme moyenne pour une femme.
Finalement, je calcule une moyenne pondérée de mon visage projeté et la moyenne du sexe selon $$im_{sexe} = \alpha \times im_{moyenne~sexe} + (1 - \alpha) \times im_{proj~sexe}.$$ Ces opérations sont faits dans le fichier

partieb/main_sex_to_me.py












Crédits supplémentaires : animation du morphage
Le professeur a dit sur le forum que animer nos morphages pourraient donner des points bonis. Voici mes résultats. On dirait que j'ai mal identifié un des points pour mon morphage avec l'homme, et je n'ai pas le temps de le changer. On se rends aussi compte de l'importance d'ajouter des points imaginaires autour des lunettes, si j'avais plus de temps, car les formes ne font plus de sens.

Crédits supplémentaire : analyse en composantes principales (20%)
Le code pour cette section est disponible dans partieb/play_with_acp.py.
On applique l'analyse en composantes principales sur les images avec la fonction
sklearn.decomposition.PCA. On redimensionne chaque image en une seule dimension. Le pourcentage de la
variance expliquée par les 10 premières composantes principales est
0.7315, 0.0415, 0.0297, 0.0250, 0.0148, 0.0111, 0.0086, 0.0081, 0.0072, 0.0060.
Si on calcule d'ACP sur les images en noir et blanc, le pourcentage de la variance expliquée par les dix premières composantes principales deviennent
0.6155, 0.0556, 0.0519, 0.0318, 0.0246, 0.0170, 0.0125, 0.0105, 0.0102, 0.0089.
On remarque que les composantes principales tirées des images en couleurs peuvent capturer plus de pourcentage de la variance en moins de paramètres. Ceci était surprennant car il y a trois fois le nombre de dimensions pour l'image en couleur. Par contre, les canaux rouges, vert et bleu sont linéairement corrélés, alors l'ACP réussit à condenser ces paramètres et aussi capturer plus de pourcentage de la variance que avec les images en noir et blanc. On a donc intérêt à garder les images en couleur. On projète les points selon les trois premières composantes et on identifie les hommes en bleu et les femmes en rouge.
CLICKER ICISi on observe la deuxième composante principale (axe $y$), c'est seulement des hommes qui ont des petites valeurs de cette composante. On présente aussi un point de vue où la séparation linéaire semble optimale.
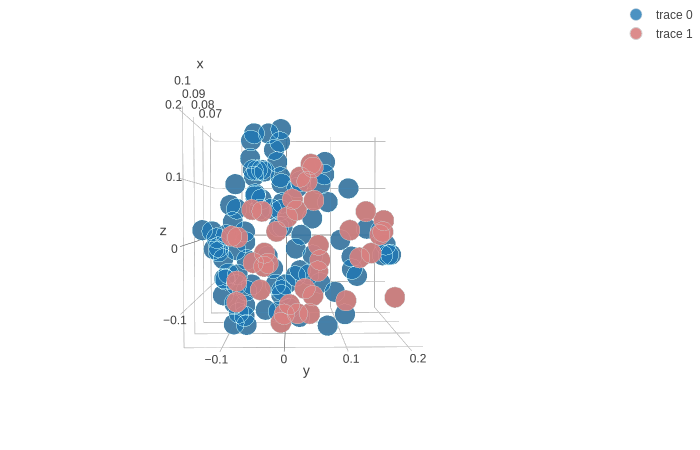
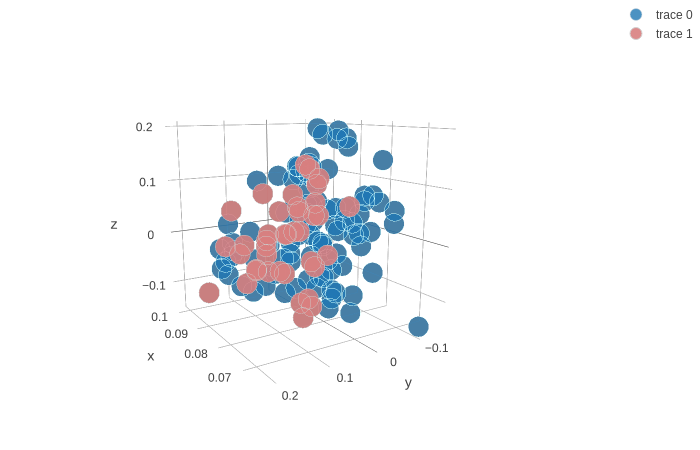
Ensuite, on change les couleurs pour avoir les sujets avec des sourires en bleu et les sujets dans sourires en rouge.
CLICKER ICIIl est très difficile d'identifier les sourires des non-sourires. En effet, comme on l'a vu en comparant les images des sujets avec un sourire et sans, il y a peu de différence globalement dans les images. Il faudrait plutot utiliser un modèle avec des filtres qui peuvent identifier des sourires ou en entraîner automatiquement.