

Avant que la photographie en couleur ne soit aussi performante qu'aujourd'hui, différentes méthodes ont été essayées
afin d'inventer cette technologie.
Sergei Mikhailovich Prokudin-Gorskii, né en 1863 en Russie, a justement consacré plusieurs années de sa vie sur ce sujet.
Au début du 20e siècle, il a pris de multiples photographies du grand Empire russe.
Sa technique consistait à prendre une même scène en 3 photos, où chacune d'entre elles comportaient
un filtre de couleur (rouge, bleu et vert). Avec ces 3 photos, il est alors possible de créer une image en couleur.
Depuis 2004, ces photographies sont désormais numérisées et accessibles sur Internet. En superposant les 3 images
de chacune de ces scènes photographiées, il est possible d'obtenir une image en couleur. Cependant, l'image obtenue
en utlisant une simple superposition comporte plusieurs défauts. En effet, il est observé que les 3 images ne
semblent pas avoir le même alignement. Voici un résultat obtenu en utilisant une superposition simple:
Il est alors désiré de développer un algorithme qui permet de déterminer un meilleur alignement entre ces photos.
Ce rapport présente les différentes méthodes employées afin de créer une image en couleur de quelques-unes des photos
de M. Prokudin-Gorskii. Cet algorithme est ensuite appliqué sur des photographies prises en 2019. Le but est de répliquer
la méthode utilisée par ce Russe. En d'autres mots, 3 photos sont prises d'une même scène et les canaux de couleur
(rouge, bleu et vert) en sont ensuite extraits. Il est alors désiré de bien aligner ces images obtenues en les alignant
de façon adéquate pour obtenir une image en couleur. Deux approches sont utilisées afin d'aborder ce problème d'alignement:
une approche à une seule échelle et une approche à échelles multiples. Ensuite, un algorithme est appliqué sur ces images
pour délimité les bordures.
Afin de déterminer le meilleur alignement entre les différentes photos d'une même scène, une approche dite à une seule
échelle est réalisée. Cette méthode consiste à effectuer une translation des images. Plus particulièrement, un filtre
est déterminé comme étant le filtre de référence. Dans cette analyse, c'est le filtre bleu. Ensuite, des translations
horizontales et verticales sont effectuées sur les deux autres filtres. Pour chacune de ces translations, un certain
pointage de performance est calculé. Ces pointages de performance sont ensuite comparés pour déterminer le meilleur
alignement. De plus, il est remarqué que les contours des photographies de M.
Prokudin-Gorskii ne devraient pas être considérés pour calculer ces critères de performance, car ils peuvent
biaiser les résultats obtenus. En effet, sachant que les 3 images n'ont pas des alignements similaires de la scène
et en remarquant que le contour des images semble souvent de mauvaise qualité, il est jugé adéquat de ne pas le prendre
en considérant lors de l'évaluation du pointage.
Pour ce qui est des translations, un maximum de 15 pixels de déplacement dans toutes les directions
(gauche, droite, haut et bas) est posé pour les images à faible résolution. Aussi, 50 pixels de chaque côté de l'image
sont utilisés pour former la bordure non considérée lors du calcul du pointage de performance.
En essayant différents nombres et en observant le contour des
différentes images analysées, le nombre de pixels (50px) est jugé adéquat dans ce contexte.
Plusieurs critères de performance peuvent être utilisés pour déterminer le meilleur alignement. Dans cette analyse,
la somme des différences au carré (norme L2) et la corrélation croisée normalisée sont utilisés. Voici les résulats
obtenus sur des images de M. Prokudin-Gorskii.
















Afin de déterminer le meilleur alignement entre les différentes photographies d'une même scène, une approche dite à échelles
multiples est également réalisée.
Dans l'analyse à une échelle, la résolution des images utilisées n'est pas très grande.
C'est pourquoi des déplacements de 15 pixels dans toutes les directions sont jugés adéquats.
Cela correspond à 312 déplacements possibles ( (15*2+1)2) ).
Si les images sont de plus grande résolution, il est nécessaire d'effectuer des déplacements plus grands que 15
pixels dans chaque direction.
Par exemple, pour une image dix fois plus grande, cela nécessiterait des 3012 déplacements possibles
( (150*2+1)2 ).
Dans cette logique, un problème est observé avec cette méthode, car le nombre de calcul peut être excessivement élevé
pour une image à bonne résolution.
Il serait alors pertinent de modifier cette approche pour de minimiser le nombre de calculs.
La méthode à échelles multiples vient justement améliorer cet aspect négatif de la méthode à échelle simple.
Pour se faire, l'image est analysée une première fois à une plus petite échelle (4 fois plus petite dans cette analyse).
Puisque l'image est 4 fois plus petites, 4 fois moins de calculs sont nécessaires pour déterminer le meilleur emplacement.
L'image est ensuite analysée à une échelle un peu moins petite (2 fois plus petite) mais en se basant sur le meilleur
emplacement déterminé lors de la première analyse. De cette façon, un maximum de 15 pixels de déplacement dans toutes
les directions est jugé adéquat pour cette deuxième analyse.
Finalement, l'image est analysée à sa pleine résolution tout en considérant le meilleur emplacement déterminé
à une échelle 2 fois plus petite. Également, un maximum de 15 pixels de déplacement dans toutes les directions est
jugé adéquat. Cette façon de procéder donne des résultats identiques (ou très similaires) à l'approche
à une seule échelle, mais de manière beaucoup plus rapide.
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 eAgrandir
eAgrandir
 Agrandir
Agrandir
 eAgrandir
eAgrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 eAgrandir
eAgrandir
 eAgrandir
eAgrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 eAgrandir
eAgrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
En analysant les images en format RGB et HSV, il est remarqué que la saturation semble être le meilleur
filtre pour distinguer le contour non désiré des images.
C'est pourquoi l'approche utilisée dans cette analyse est basée sur la différence saturation entre 2 lignes
(pour déterminer la bordure horizontale) ou entre 2 colonnes (pour déterminer la bordure verticale).
Par contre, pour avoir une meilleure comparaison entre les différentes images analysées, c'est la différence de saturation (entre 2
colonnes/lignes) divisée par la moyenne de saturation de l'image au complet qui est utilisée comme critère.
Ce critère est nommé différence de saturation ajustée.
Les bordures se situent où cette différences de saturation ajustée est élevée.
Ainsi, la méthode utilisée dans ce rapport délimite les bordures vericales et horizontales lorsque la différence ajustée
est supérieure à certain seuil. Ce seuil, qui est de 0.07, est le même pour toutes les images.
C'est avec essais et erreurs que ce seuil est jugé adéquat lorsque sa valeur est 0.07.
Puisqu'il n'est pas nécessaire de comparer toutes les lignes et colonnes, les calculs sont limités à 450 pixels
dans toutes les directions (haut, bas, gauche, droit). Voici les résulats obtenus:
 Agrandir
Agrandir
 Agrandir
Agrandir
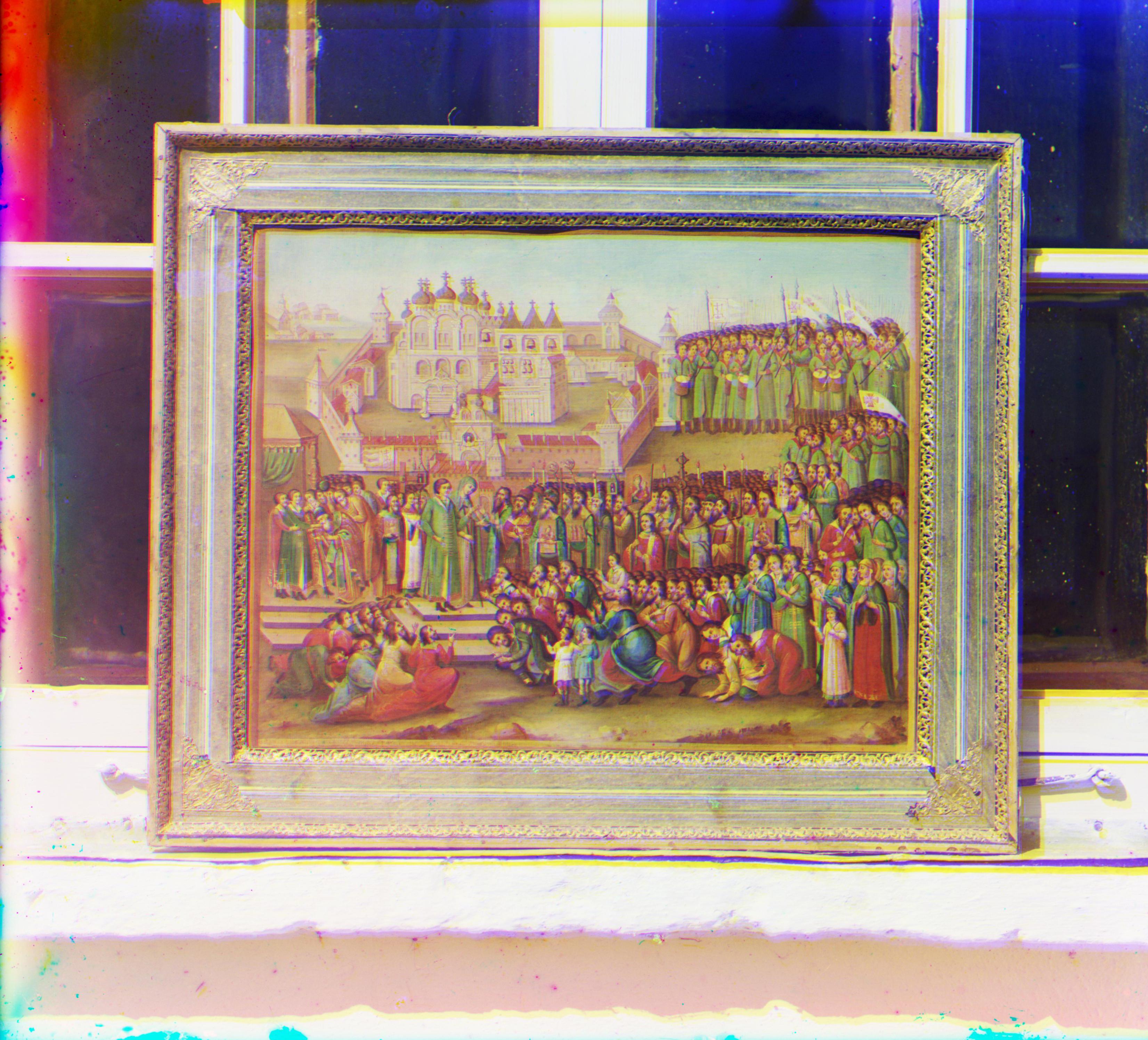 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 eAgrandir
eAgrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
 Agrandir
Agrandir
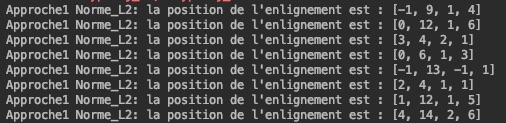
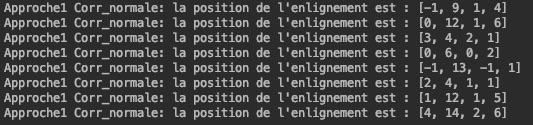
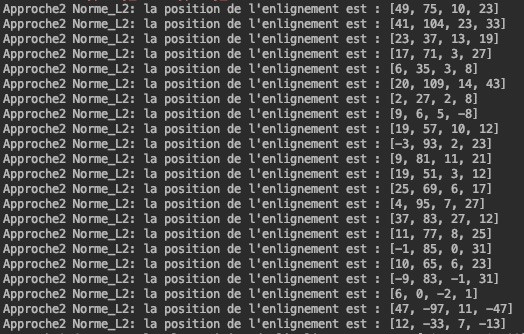
Voici les alignements obtenus pour les méthodes de la somme des différences au carré (Norme_L2) et de la
corrélation normale croisée (Corr_normale) :
Approche à une échelle
Approche à échelles multiples
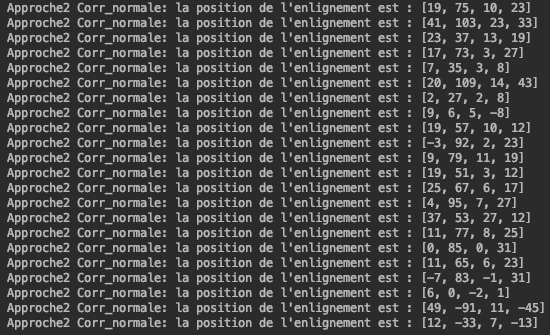
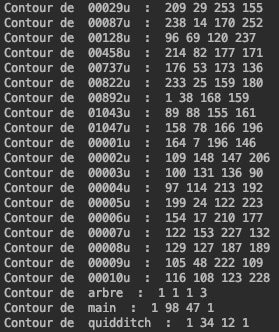
Voici les résultats obtenus pour déterminer les bordures des images en couleur:
Différence de saturation ajustée
En obervant les images obtenues, les méthodes de différence au carré et de corrélation normale croisée semblent donner
des résultats identiques et il est difficile de déterminer laquelles de ces méthodes donne de meilleurs résultats.
Aussi, en analysant les alignements obtenus, il est remarqué qu'ils sont très similaires peu
importe le critère de performance choisi. Puisque le critère de différence au carré requiert un calcul plus simple,
cette méthode est considérée plus efficace et donc meilleure.
Considérant que seule une analyse à 2 dimensions (horizontal et vertical) est effectuée pour détecter les bordures,
la méthode utilisée semble efficace.
Les résultats obtenus dans cette analyse ne sont pas parfaits et plusieurs aspects peuvent être améliorés.
Il serait pertinent de faire une analyse sur la différence d'échelle entre les canaux de couleur.
Plus exactement, si une photographie est prise de quelques centimètre ou millimètres plus loin que les deux autres
photographies, cette différence peut être observable à l'oeil nu sur l'image en couleur obtenue.
Aussi, il serait pertinent d'analayser l'angle entre les diférents canaux de couleur.
En effet, si une petite rotation est effectuée entre les canaux de couleur, cette différence peut également être
observable à l'oeil nu sur l'image en couleur obtenue.
Ces deux aspects d'amélioration mentionnés (échelle de grandeur et angle de rotation) visent à contrer le fait que
les photographies n'ont pas tout à fait la même prise de vue de la scène. Toutefois, il est remarqué
que les images en couleur obtenues dans cette analyse ne sont pas optimales à cause de certaines imperfections, et
non à cause d'une prise de vue différente. Par exemple, certaines tâches sont présentes.