
Le but de mon projet est de faire de la réalité augmentée en me basant sur la reconstruction 3D d'une scène. C'est en quelque sorte une version améliorée du projet sur lequel j'ai travaillé durant mon stage au laboratoire de vision de l'Université Laval. Les grandes étapes permettant d'arriver à mon but sont les suivantes:
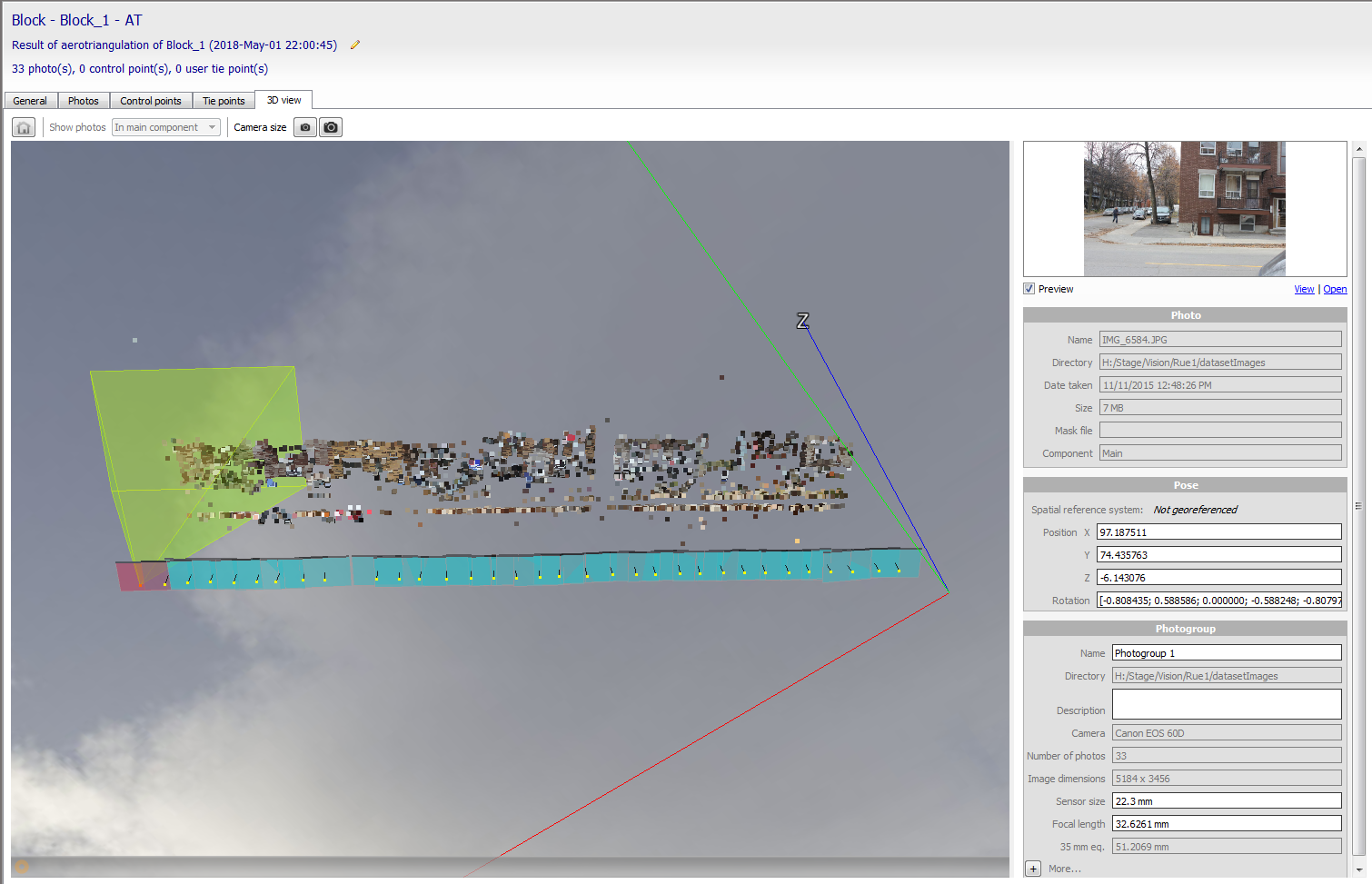
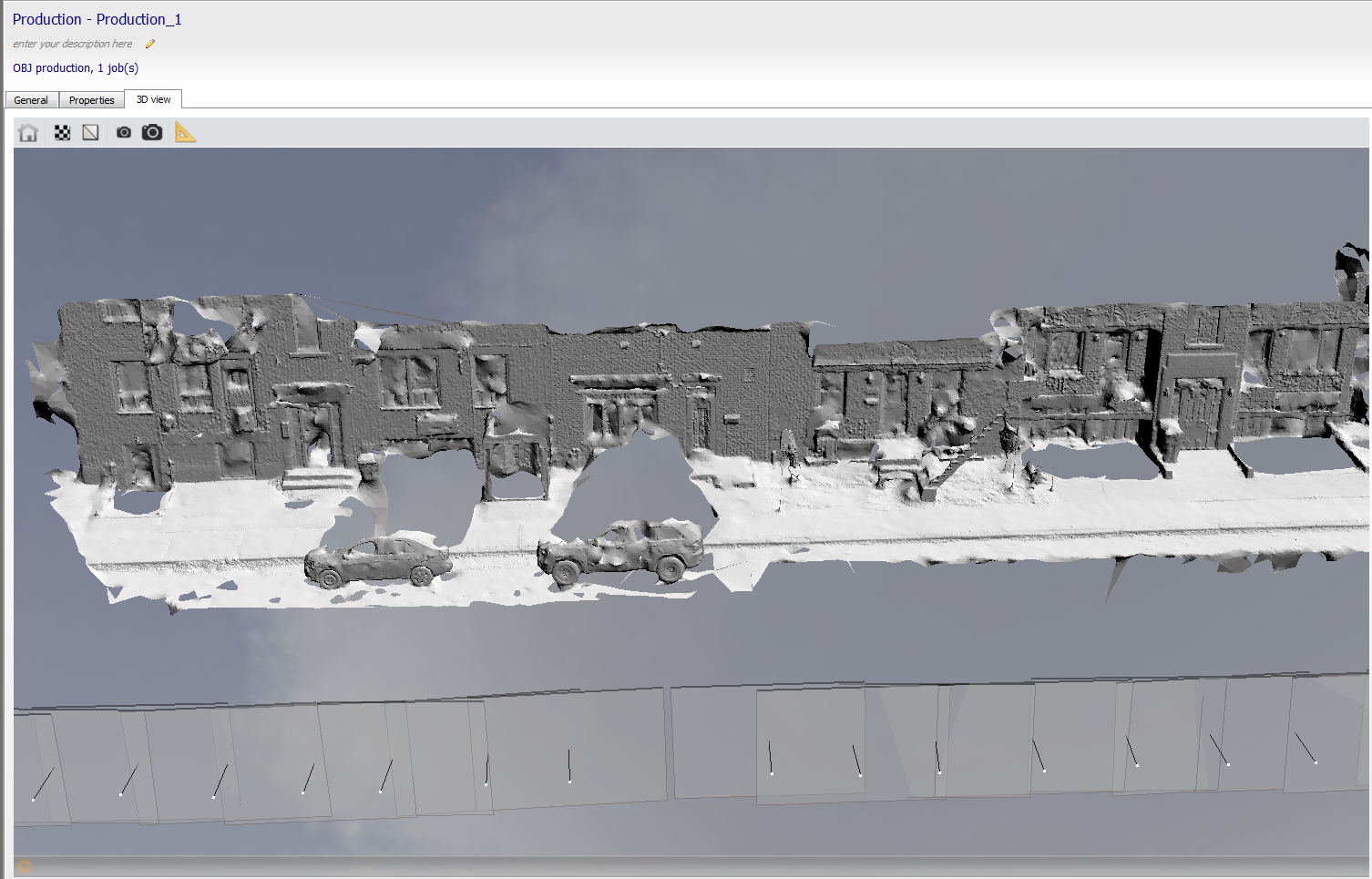
Pour construire un modèle 3D de la scène, j'utilise le logiciel ContexteCapture développé par la compagnie BentleySystems. Ce logiciel permet de reconstruire un modèle 3D à partir de plusieurs images d'une scène. En général, ce type de logiciel utilise une approche semblable au SfM, c'est-à-dire qu'à partir des correspondances entre les images, l'algorithme va retrouver à la fois le déplacement de la caméra et les points 3D associées aux correspondances. Bien sûr, pour que la reconstruction fonctionne, les images doivent se chevaucher suffisamment et il doit y avoir un nombre suffisant de points d'intérêts distinctifs dans la scène. De base, le SfM permet seulement de reconstruire une version clairsemée du modèle 3D car seulement les correspondances sont reconstruites. Un autre algorithme doit donc être utilisé afin de compléter le modèle et obtenir une version dense. Voici donc un exemple de résultat obtenu par le logiciel:
et voici un extrait des images qui ont été utilisées pour la reconstruction.




Pour plusieurs raisons, comme le fait que des points ne soient tout simplement pas visibles dans les photos, la reconstruction n'est absolument pas parfaite. Cependant, elle devrait être suffisament bonne pour permettre une localisation assez précise de la caméra.
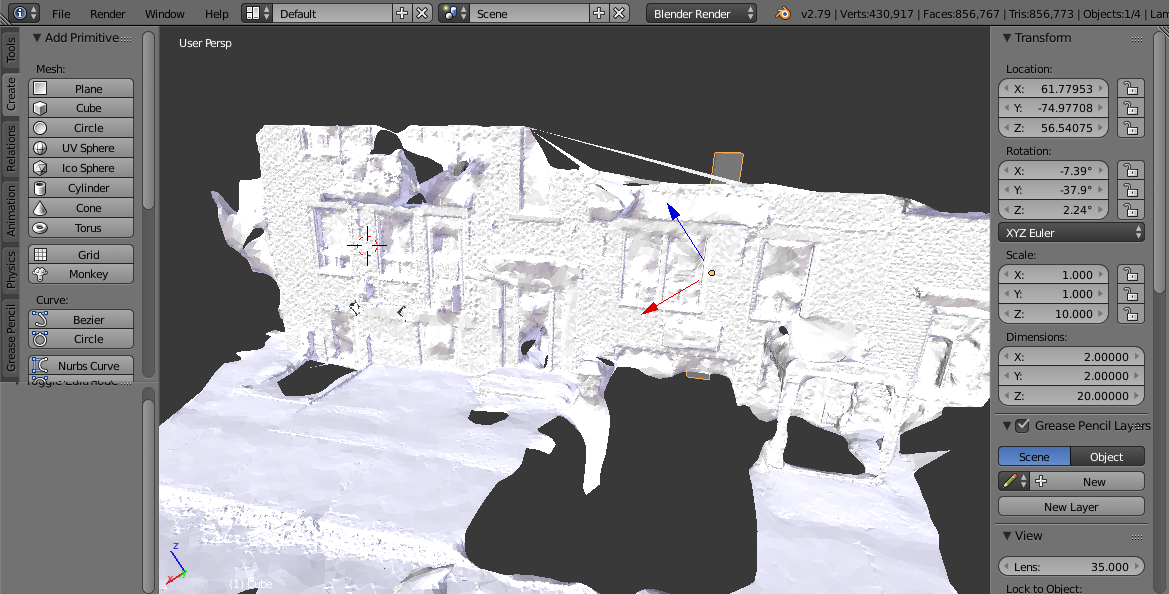
Cette étape, consistant à placer l'objet à augmenter dans la scène reconstruite, sert à exprimer les coordonnées de l'objet virtuel dans le repère de la scène. Ces coordonnées seront ensuite utilisées au moment d'augmenter l'image en tant que tel. Puisque le but de mon projet est de bien positionner le modèle virtuel dans l'image et non de présenter un rendu riche et réaliste, j'utilise un modèle virtuel très simple(comme un cylindre). Voici un exemple d'objet virtuel placé dans la scène reconstruite:
Pour cette étape, je me suis basé en partie sur l'article de Sattler et coll. intitulé Fast Image-Based Localization using Direct 2D-to-3D Matching paru en 2011. En résumé, l'algorithme fonctionne de la façon suivante:
Une fois la pose de la caméra retrouvée, il reste à reprojeter les coordonnées 3D du modèle virtuel en utilisant les bons paramètres de caméra(intrinsèques et extrinsèques(pose)) J'obtiens donc les coordonnées 2D du modèle dans l'image courante qu'il suffit de relier pour créer une image augmentée. À défaut d'avoir réussi à obtenir un bon résultat pour les données présentes, voici le type de résultat que j'avais obtenu dans mon stage:



