
| 
|
Pour le projet, j'ai choisi d'implémenter la solution de l'article From Motion Blur to Motion Flow: a Deep Learning Solution for Removing
Heterogeneous Motion Blur de Dong Gong, Jie Yang, Lingqiao Liu, Yanning Zhang, Ian Reid, Chunhua Shen, Anton van den Hengel, Qinfeng Shi of
School of Computer Science and Engineering, Northwestern Polytechnical University, China and the University of Adelaide, Australian Centre
for Robotic Vision.
Cet article permet d'estimer le bruit de déplacement sur une image et de le soustraite à une image bruitée pour retrouver une image plus nette.
Quand on prend une photo d'une image et que les acteurs sont en déplacement, on peut capturer du bruit. En effet, si leur déplacement est plus
rapide que la vitesse d'obturation de l'appareil photo, alors les photos qui seront capturés laisseront voir des traînées que l'on appelle du
"motion blur". Ce bruit peut être qualifié en 2 types:
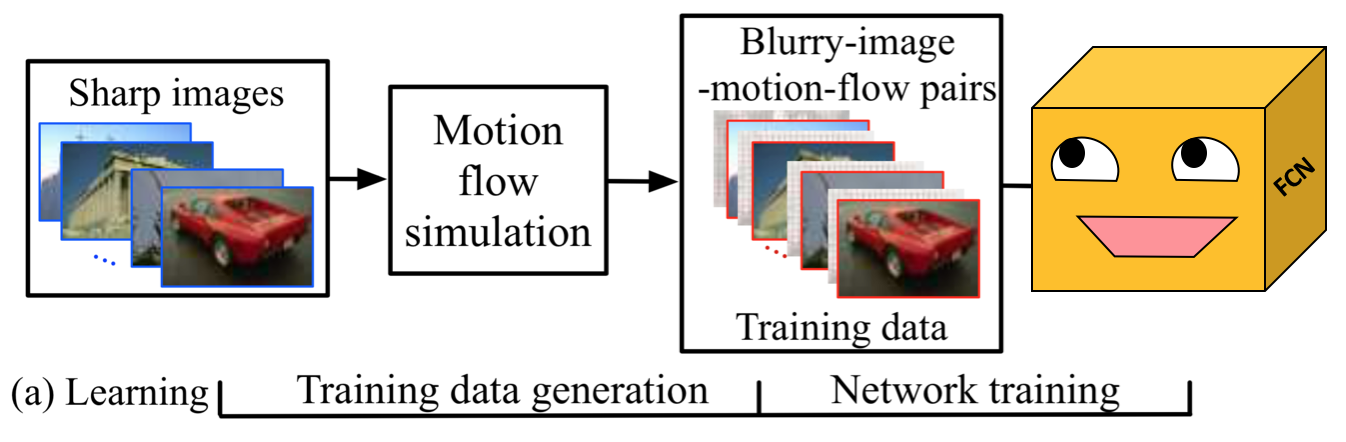
La méthode de l'article se fait en 2 étapes. La première étape consiste à créer le jeu de données et à entraîner le réseau avec ce dernier. La seconde consiste à estimer le bruit dans l'image puis de le retirer avec des algorithmes linéaires.
Pour créer le jeu de données, les images de BSD500 ont été utilisées. Il s'agit d'un ensemble de 200 images qui sont d'une taille d'environ 300 x 460 et qui représentent des animaux, des hommes ou des scènes. En prenant les 200 images et en utilisant les algorithmes dont l'article fait usage, il est possible de générer 50 motion flow par image. Cela totalise 10 000 motion flow en plus des 200 images non-bruitées et leurs motion flows associés (qui sont nuls).
|
|
|
En plus du bruit de déplacement directionnel ajouté à l'image, un bruit gaussien est ajouté ce qui rend l'image un peu plus floue et garantie
que l'image ne peut être débruitée.
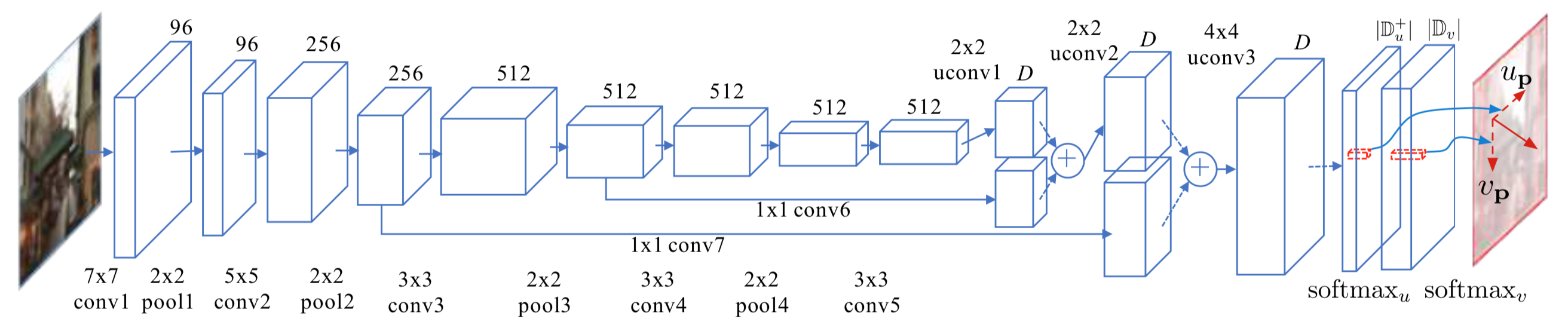
Dans l'article, un modèle entraîné par l'équipe est donné, mais il est sur Caffe. Comme j'ai décidé de l'implémenter en Pytorch, je dois réecrire le code et déterminer les équivalences pour les différentes fonctions.
En plus du déplacement directionnel ajouté à l'image, un bruit gaussien est appliqué ce qui rend l'image un peu plus floue et garantie
que l'image ne peut être débruitée facilement.
L'entraînement implique plusieurs paramètres:
Pour l'entraînement, le réseau de neurone prend en entrée des images motion blurred et tente de prédire en sortie le motion flow map qui est associé à cette image. Comme tous les bruits ont été générés synthétiquement, les labels ont été conservés et il est possible de calculer la différence entre la prédiction et la "ground truth" (la cible) avec une perte de Cross Entropy.
Pour chaque image blurred, le réseau apprend à prédire le bon motion flow map. Itérativement et avec la descente de gradient, il devient meilleur et devrait prédire des motion flow maps qui sont de plus en plus en accord avec le bruit réel dans l'image.
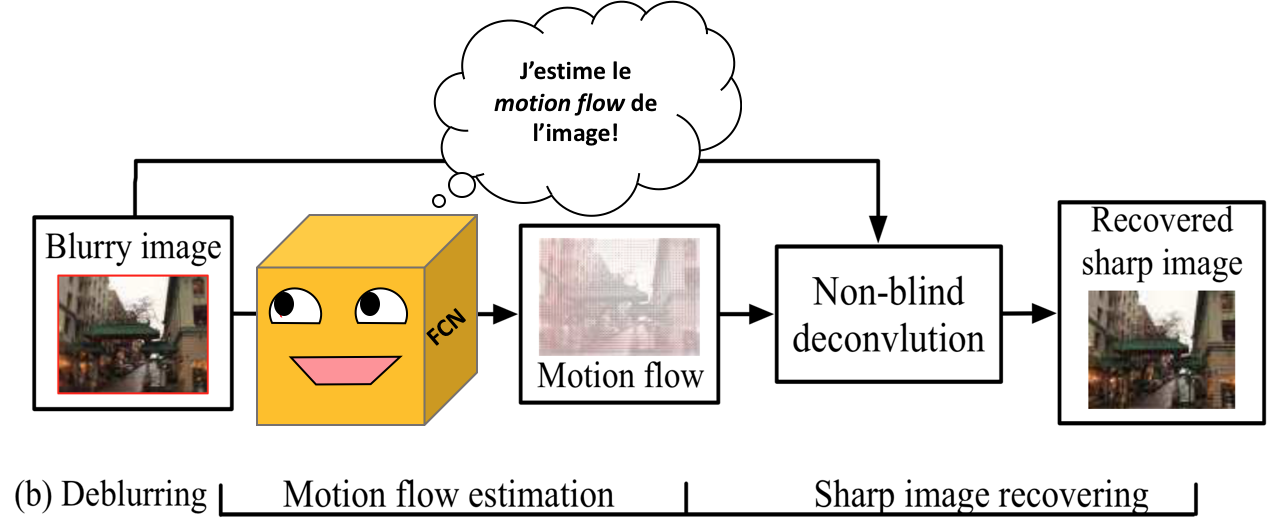
Pour retirer le bruit d'une image, il faut tout d'abord prendre le motion flow map qui a été estimé par le modèle. Par après, en prenant le déplacement de chacun des pixels, un algorithme se charge de calculer linéairement le déplacement pour le pixel et ses voisins. Ce processus se fait par déconvolution. Il est à noter que la déconvolution peut occasionner des effets indésirables sur les photos. En effet, la déconvolution effectue du upsampling dans l'image. Cela implique d'aggrandir une image en lui rajoutant de l'information et ce processus peut injecter du bruit, car du padding doit être ajouté autour de l'image. Parfois, si le upsampling est trop grand, on peut appercevoir un effet de quadrillage sur le résultat final.
L'entraînement du réseau est très long, car chaque epoch prend environ 40 minutes à s'exécuter. En prenant en considération que les auteurs de l'article ont mis 65 epoch pour atteindre la convergence, cela implique 45 heures de calculs. De ce fait, j'effectue une comparaison des résultats qui sont obtenus avec leur modèle en Caffe à ceux que j'ai obtenu. Aussi, il est à prendre en considération que le modèle que j'utilise fait usage d'un modèle qui est peu entraîné (environ 16 epoch), car il s'agit de la meilleure accuracy qui a été obtenue. Les résultats ne sont donc pas parfaits.

Avec le modèle de l'article, on constate que le motion flow map est très représentatif du bruit de l'image et que le réalignement des pixels
se fait très bien. Le résultat du deblurring pour mon image avec un bruit aléatoire est très réussie.

Mon modèle, bien que sous-entraîné, laisse paraître un bon présage sur son apprentissage, car tous les vecteurs estimés dans le motion flow map
sont orientés dans la bonne direction. On peut le comparer avec l'image précédente et le motion flow estimé par le modèle complètement entraîné.
Ce qui manque à mon modèle encore, c'est un certain facteur de gain sur les vecteurs estimés. En effet, l'orientation est bonne, mais la norme
est encore beaucoup trop petite. Néanmoins, on voit que le déblurring fonctionne en partie, car l'image est un peu plus nette.
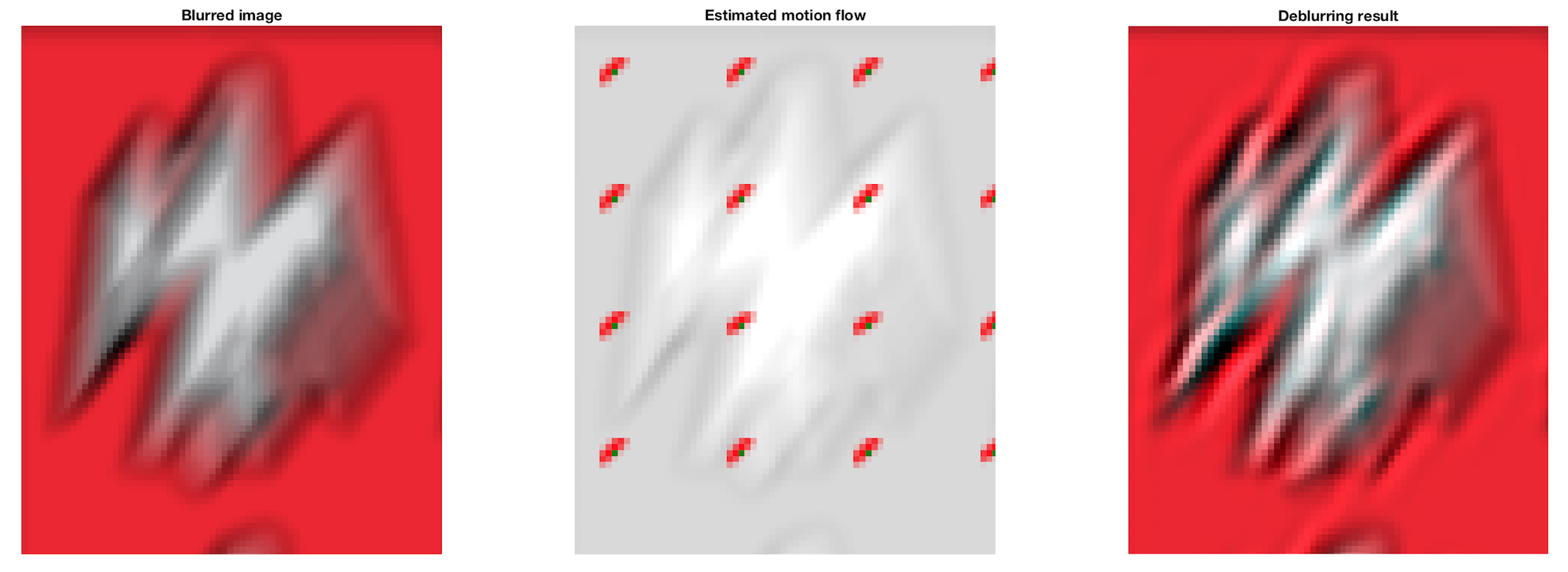
Un agrandissement de l'image précédente pour 2 régions indentiques sur les images permet de bien voir l'effet du deblurring. On retrouve beaucoup
d'information au niveau des bordures.
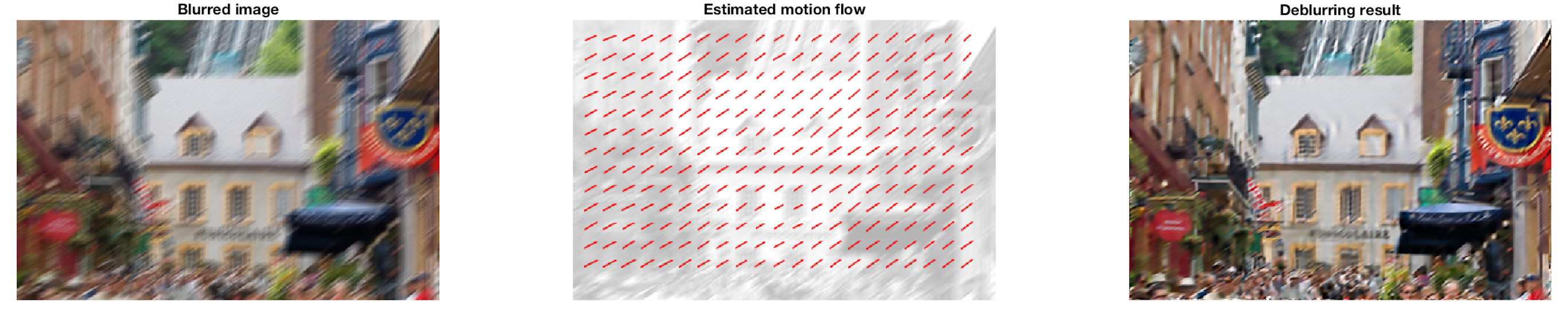
Une fois de plus, les performances avec leur modèle entraîné sont très impressionnantes. J'ai choisi cette photo, car elle contenait un peu de bruit
dans l'image originale et qu'il y avait plusieurs écritures sur des panneaux d'affichage. Le bruit généré est aléatoire. Le retrait du bruit dans l'image
ne permet pas de reconnaître les écritures sur les panneaux. Toutefois, avec le retrait du flou, on retrouve beaucoup d'information au niveau des visages
des gens.
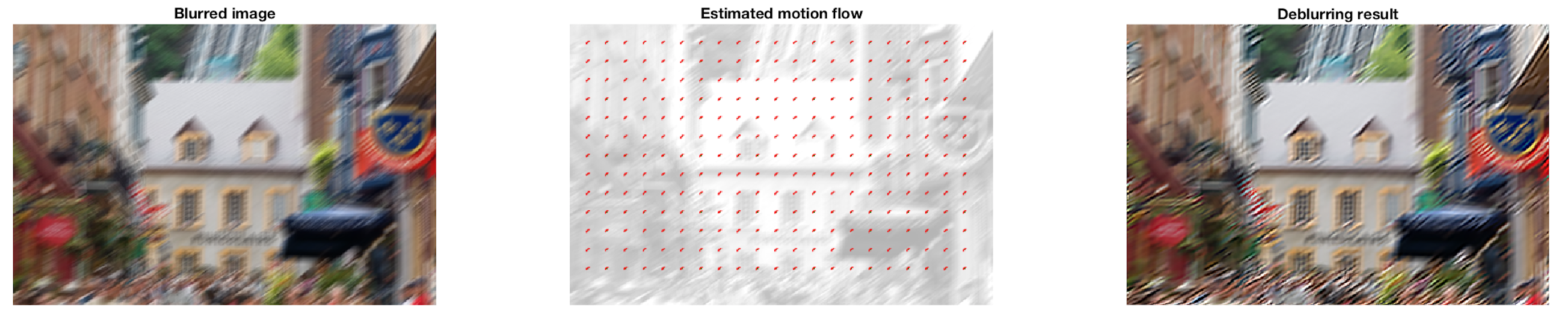
Les performances du réseau entraîné sont très basses encore, mais les vecteurs ont sensiblement tous la bonne orientation.

Et si je prenais une photo d'un objet en mouvement? Un objet qui aurait du motion blur naturel. Voici le résultat de ma tentative. Le problème avec
une photo d'un appareil, c'est qu'elle est de très grande résolution. L'estimation du motion flow se fait bien avec le réseau, même si l'image est
de plus grande taille. Toutefois, c'est beaucoup plus long. En effet, c'est aussi pourquoi elle doivent être rapetissées, car le traitement devient
interminable pour le deblurring. Il faut donc faire un resizing de l'image. Malgré les effets du resize, on peut constater que les résultats sont
vraiment impressionnant. J'agitais effectivement la canette de haut en bas. Par contre... rien n'explique la présence des vecteurs au bas à gauche.

Une fois... ça va... 2 fois, c'est pas pire. Mais 3 fois que les vecteurs quasiment dans la même orientation? Je commence à douter de mon epoch 7 !
Je retesterai avec le réseau complètement entraîné. Le résultat devrait être plus prometteur. Au moins, j'aurai tenté l'expérience!
La première limitation au modèle courant est que le modèle ne peut pas complètement retirer le flou de l'image. En effet, le modèle peut
au mieux estimer le bruit et ne peut pas le retirer complètement. Aussi, il est à prendre en considération que le bruit gaussien ne peut
être retiré.
La seconde limitation au modèle est que le domaine est borné et limité dans l’axe des X. Si X < 0, alors X = - X. Cela implique que les déplacements
sur l'axe des X peut seulement être positif. Cela facilite l'entraînement, mais implique que les flou dans l'autre direction seront augmentés plutôt
que retirés. Aussi, le déplacement maximal des vecteurs (soit la vitesse occasionnant le bruit) est limitée à une valeur maximale. De ce fait, si du
bruit de déplacement est trop élevé pour les paramètres d'entraînement, il ne pourra pas être bien atténué.
Premièrement, les filtres à déconvolution sont suivi d'un upsample, car la conversion entre les fonctions de Caffe et de Pytorch ne sont idéales. Le problème est
qu'en rajoutant des layers de upsampling à des régions de déconvolution, c'est l'équivalent à rajouter de nouvelles couches de déconvolution. Comme
chaque couche peut occasionner du bruit en forme de damier, il faut limiter les opérations de déconvolution. Il faudrait donc réussir à obtenir la
même équivalence entre les fonctions de Caffe et Pytorch.
Deuxièmement, du dropout pourrait être ajouté à l'entraînement pour le régulariser. Cela pourrait rendre le réseau meilleur dans les généralisations et les cas qui
sont particuliers. En éteignant des neurones aléatoirement, on vient forcer l'utilisation de tous les neurones dans le réseau plutôt que de concentrer
le gradient dans des neurones particuliers.
Troisièmenent, le taux d'apprentissage devraient être réduit au cours de l'entraînement. Toutefois, le training a été lancé sur Pytorch sans l'ajout de
ce paramètre. Cela pourrait nuire à la convergence, car le taux d'apprentissage pourrait être trop élevé pour atteindre les minimums locaux après un haut
nombre d'epochs.
Finalement, il faudrait retravailler les valeurs de domaine pour l'entraînement, car elles limitent les valeurs maximales de motion blur ainsi que leurs
directions.