Par Gabriel Leclerc 111 044 929
Ce projet est basé sur l’article de Gatys et al .
Il présente une approche basée sur le réseau VGG19 pré-entraîné sur le jeu de données ImageNet .
Le but de l’article est d’appliquer le style d’une image dans une autre image.
Les auteurs développent une représentation de style et une représentation de contenu. Cinq représentations de style sont calculées à partir de l’image de style et une seule représentation de contenu pour l’image que l’on souhaite transférer le style. L’erreur est propagée seulement sur les pixels de l’image en entrée.
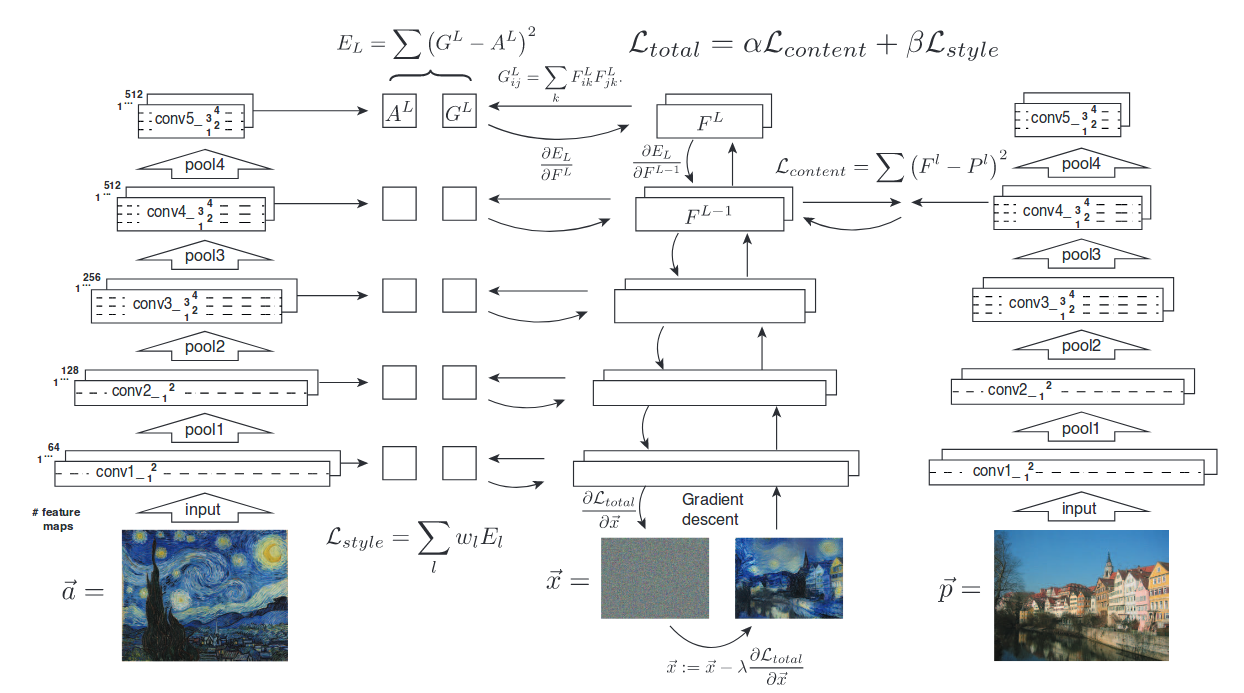
Voici une image de l’article qui montre bien leur approche.
Les matrices A et G sont les représentations de style de l’image de style (à droite) et de l’image générée respectivement. Les matrices F et P sont les représentations de contenu pour l’image générée et l’image de contenu (à droite). La moyenne des différences au carré est utilisée pour déterminer la perte de représentation. Finalement, il est possible d’ajuster l’importance accordée au style et au contenu avec les hyperparamètres alpha et beta.
La représentation de style pour une couche est en fait le calcul de la matrice de Gram du tenseur de sortie après la couche de convolution. Par exemple, pour une couche convolutionnelle de 64 filtres, la matrice de Gram est de 64x64 . Chaque élément de cette matrice est le ‘produit scalaire’ entre deux features map , c’est-à-dire la somme du produit élément par élément.
La représentation de contenu pour une certaine couche est simplement le feature map créé par le réseau directement.
Voici une image de l’article qui montre l’effet du choix de la couche de convolution pour la représentation du contenu.

L’image du haut utilise une couche mois profonde dans VGG, les détails sont mieux conservés.
L’image suivante illustre très bien l’information contenue dans les représentations.

Les images du haut et du bas sont les images sont les images, déterminées itérativement, qui ont une représentation la plus semblable possible. On voit que pour les cinqs couches du réseau, la représentation de contenu contient assez d’informations pour générer à peu près la même image d’entrée. Pour la représentation de style, on voit clairement ce que chaque couche va chercher comme style dans l’image de style d’entrée. On remarque bien l’importance d’utiliser toutes les couches pour effectuer le transfert de style.
Pour générer l’image, le calcul de l’erreur totale, soit l’erreur de style et l’erreur de contenu, est effectué pour une image aléatoire. Dans PyTorch, il est important de ne pas calculer de gradient pour les paramètres du réseau (on ne l’est modifie pas), uniquement sur les pixels de l’image en entrée. Maintenant que que l’on connait l’erreur, on propage l’erreur sur les pixels de l’image. La mise-à-jour des pixels se fait avec l’optimiseur L-BFGS (les auteurs suggèrent d’utiliser cet optimiseur afin d’obtenir de meilleurs résultats). On effectue itérativement la mise-à-jour des pixels jusqu’à ce qu’un critère d’arrêt soit atteint. Comme les auteurs ne mentionnent pas leur critère d’arrêt, j’ai décidé d’effectuer 2000 itérations.
Généralement, obtenir des résultats presque identique à ceux dans l’article était vraiment difficile pour plusieurs raisons. Tout d’abord, leurs résultats sont générés à partir d’image aléatoire (leur seed n’est pas donnée), cela à pour effet d’avoir des images finales différentes d’un teste à l’autre. De plus, il ne donne pas leur critère d’arrêt pour la génération de l’image. J’ai tout de même réussi à obtenir des résultats semblables. L’image du centre représente le résultat de l’article et celle à droite, mon résultat.

Ce résultat est vraimenet satisfaisant.

Pour ce résultat, je trouve que mon image générée contient trop d’information sur le style, par exemple, la section en bas à gauche ne représente pas assez l’image de contenu.

Pour cette image, l’initialisation aléatoire de l’image avait beaucoup d’impact sur la direction des ‘vagues’ dans le ciel.

Le résultat est plutôt bien, par contre, je n’ai pas assez donné d’importance au style.

Finalement, je trouve que l’article donnait beaucoup trop d’importance au style pour cette photo. J’ai ajusté la mienne pour obtenir un résultat semblable.
Pour cette section, je me suis amusé à essayer différents styles sur mes photos et des photos prises sur le net.
Comme premier teste (idée de Mohammed, celui sur la photo originale), j’utilise une photo des Simpsons comme style et je l’applique à plusieurs de mes amis.

Je trouve l’effet vraiment original. De loin, on a l’impression de voir plusieurs personnages des simpsons empilés, mais en regardant attentivement, on remarque que les détails ne sont pas cohérents entre eux.
Ensuite, par accident, j’ai appliqué ma soeur comme style sur l’image.

L’image générée comporte des yeux un peu partout dans celle-ci. Le résultat à une allure psychédélique.
Pour tester la méthode, j’ai décidé d’appliquer le chat de ma soeur sur la photo de celle-ci.

Encore une fois, le résultat fait un peu peur. On remarque que l’algorithme ne peut pas appliquer le visage du chat sur le visage d’un humain comme un masque. C’est normal, puisque la représentation de style ne va conserve pas cette structure sémantique de la photo de style.
J’ai aussi appliqué un style spatial sur la photo de Hulk .

Le résultat est vraiment impressionnant. Ce qui m’impresionne le plus est la présence des étoiles dans les zones de hautes fréquences (contour de Hulk, ses veines).
Par curiosité, j’ai essayé de colorer Albert avec un viel homme .

Pour ce teste, j’ai utilisé la première couche du réseau pour la représentation du contenu. Comme expliqué dans l’exemple avec ma soeur et son chat, le réseau est construit pour transférer un style dans une autre image uniquement.
Finalement, suite aux commentaires pendant la présentation orale, j’ai essayé d’utiliser la même image comme style et contenu. Voici le résultat.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}