TP4: Assemblage de photos
Partie 0: Réchauffement
Dans cette partie, il faut créer un fonction appliqueTransformation(img, H) pour appliquer une homographie sur une photo quelconque. Pour ce faire, les étapes de transformations sont similaires aux étapes rencontrées dans le TP3 lors du morphage de visage. Or, il faut maintenant créer un nouveau cadre d'image ayant les dimensions nécessaires pour contenir notre image transformée.
- En premier, nous transformons les 4 coins de notre image d'entrée avec l'homographie . Il suffit de faire un produit matriciel en ayant préalablement changé les 4 points en coordonnées homogènes.
- Avec la transformation des 4 coins , nous pouvons calculer la hauteur et la largeur de notre image transformée . Avec la formule où sont les coordonnées en y des 4 coins et sont les coordonées en x correspondantes :
- Il est important de garder une référence et puisque le point minimum )sera situé à l'origine de la nouvelle image.
- La dernière étape est celle qui s'approche le plus de ce qui a été fait dans le TP3. Nous créons un mesh de l'image de destination et nous interpolons les couleurs en transformant toutes les coordonnées avec l'homographie inverse. Il est important d'ajouter à tous les points afin de refléter le nouveau point à l'origine de l'image :
Résultat avec l'image donnée
- Implémentation du morphage :
code/n0.py - Commande :
python code/n0.py
| Avant H | Après H |
|---|---|
 |  |
Discussion : Comme on voit, notre algorithme produit le résultat escompté. Nous pouvons voir que le cadrage final est le plus petit possible puisqu'il entoure tout juste l'image finale.
Partie 1: Appariement manuel
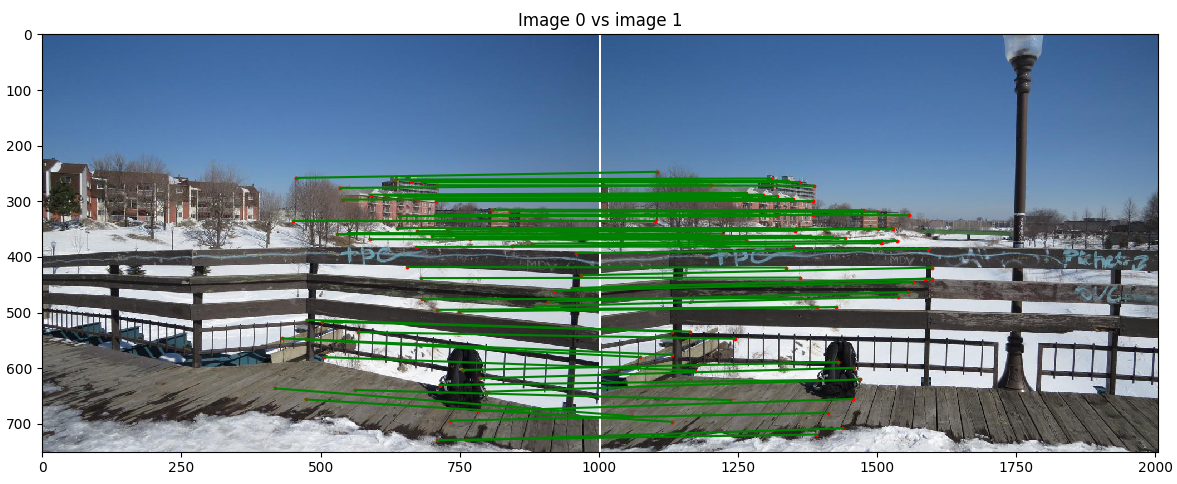
Dans cette partie, il faut non-seulement utiliser l'approche de la Partie 1 pour transformer l'image, mais il faut également trouver la bonne transformation projective entre les images formant le panorama. Rappelons que nous désirons trouver la transformation projective qui contient 8 degrés de liberté. Ainsi, pour trouver la transformation nécessaire (homographie) entre deux images, il suffit d'avoir 4 points de correspondance entre les images. Tout au long du TP, pour avoir plus de robustesse, nous calculerons notre transformation avec 8 points de correspondance pour plus de robustesse. Puisque les points sont sélectionnés manuellement pour cette partie, les étapes sont :
Donner manuellement 8 points de correspondance au programme par paire d'images
Calculer les homographies entre chaque paire d'image :
Nous savons que pour appliquer une homographie sur un point en coordonnée homogène, il faut faire :
Si nous traduisons en équations la matrice et développons pour construire un système d'équation :
Comme il est proposé dans l'énoncé de laboratoire, nous pouvons assumer que , après avoir réarangé l'équation :
Le système d'équation linéaire est ainsi très facile à construire :
Il suffit de résoudre le système avec la méthode des moindres carrés avec python
numpy.linalg.lstsq. Il est noter que l'astuce du a été utilisé ici pour avoir une solution autre que la solution triviale avec les moindres. Il aurait été également possible de garder la variable inconnue et d'utiliser un autre algorithme de résolution.
Assembler les images avec notre algorithme décrit dans la partie 1. Puisque dans les scènes suivantes, nous aurons que 3 images à la suite de l'autre, nous utilisons un algorithme naïf qui choisi l'image du centre comme référence de projection. Il faut faire attention de bien changer la nouvelle référence avant de faire le dernier assemblage.
Résultat avec les scènes fournies
Scène 1 : Rivière St-Charles 1
Implémentation du morphage :
code/n1.pyCommande :
python code/n1.py 1
Discussion : Le résultat est assez concluent, malgré les quelques imperfections. Il y a quelques disconstinuités à cause des imperfections des lentilles aux frontières des images.
Il est d'ailleurs à noter que, tout au long du TP, nous pourrons observer le même phénomène. À un seul endroit, où les photos choisies proviennent d'un jeu de données où les images on été préalablement traitées, le phénomène ne sera pas perceptible.
Il y a également un peu de flou au centre, provenant probablement du fait que nos points n'étaient pas parfaitemement sélectionnés. Finalement, il y a une aberration sur le haut du lampadaires provenant du fait que l'effet des erreurs de transformation est amplifié proche des bords de l'image.
- Scène 2 : Plaine d'Abraham
- Implémentation du morphage :
code/n1.py - Commande :
python code/n1.py 2
Comparaison IMG_2426.JPG - IMG_2427.JPG 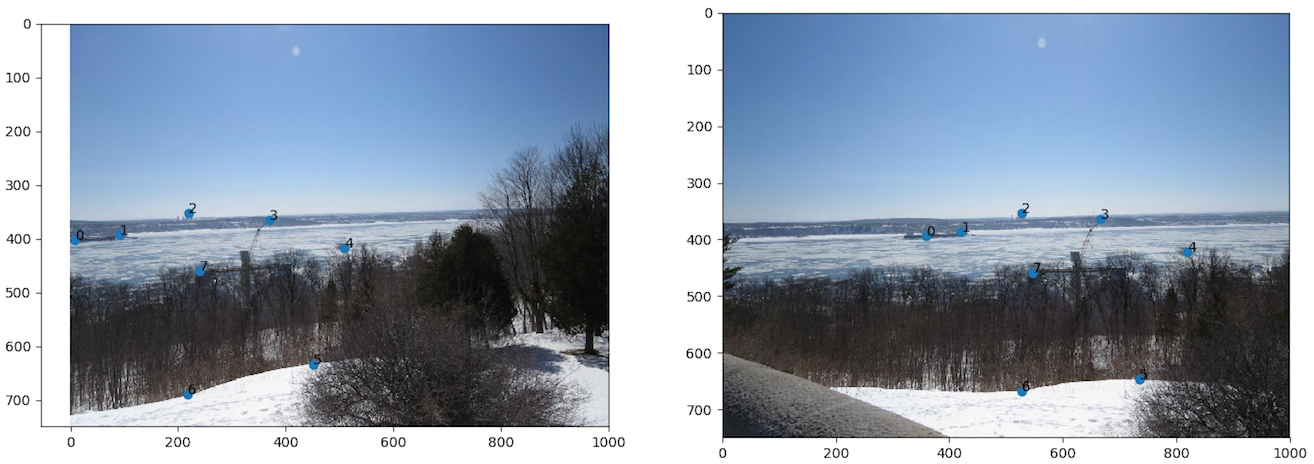 |
|---|
Comparaison IMG_2426.JPG - IMG_2427.JPG 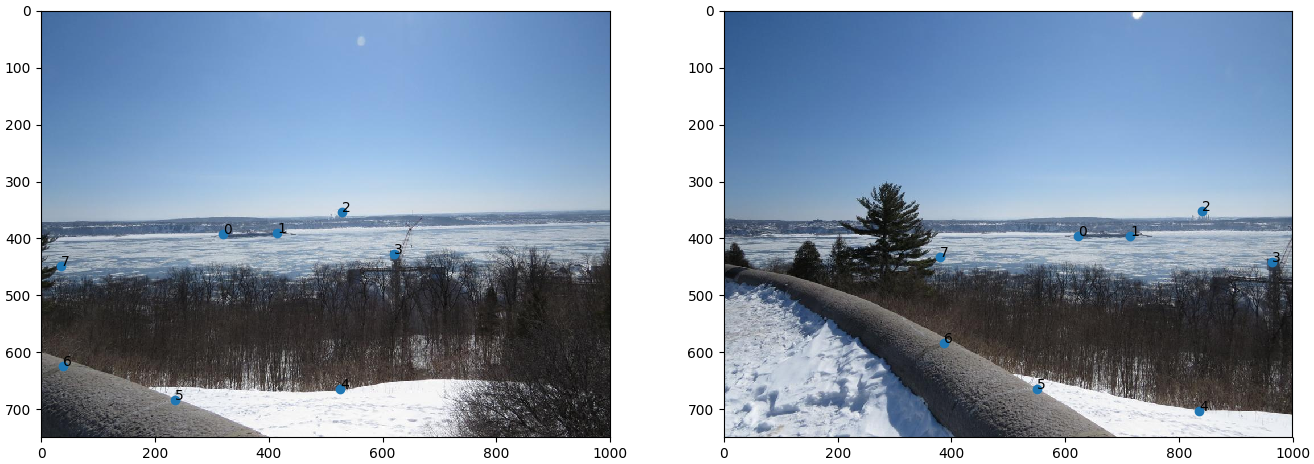 |

Discussion : Ici le résultat est encore très bon. Il y a toujours un peu de flou au centre puisque les points étaient difficiles à choisir à la main. Une chose intéressante à observer sont les taches dans le ciel. La tache de l'image IMG_2427.JPG est peut-être la capture du soleil, or il ne faut pas prendre les autres pour un soleil pris à faible exposition. Il s'agit de reflet du soleil et il est ainsi normal que ces taches ne soient pas confondues dans le panorama.
- Scène 3 : Rivière St-Charles 2
- Implémentation du morphage :
code/n1.py - Commande :
python code/n1.py 3
Comparaison IMG_2409.JPG IMG_2410.JPG 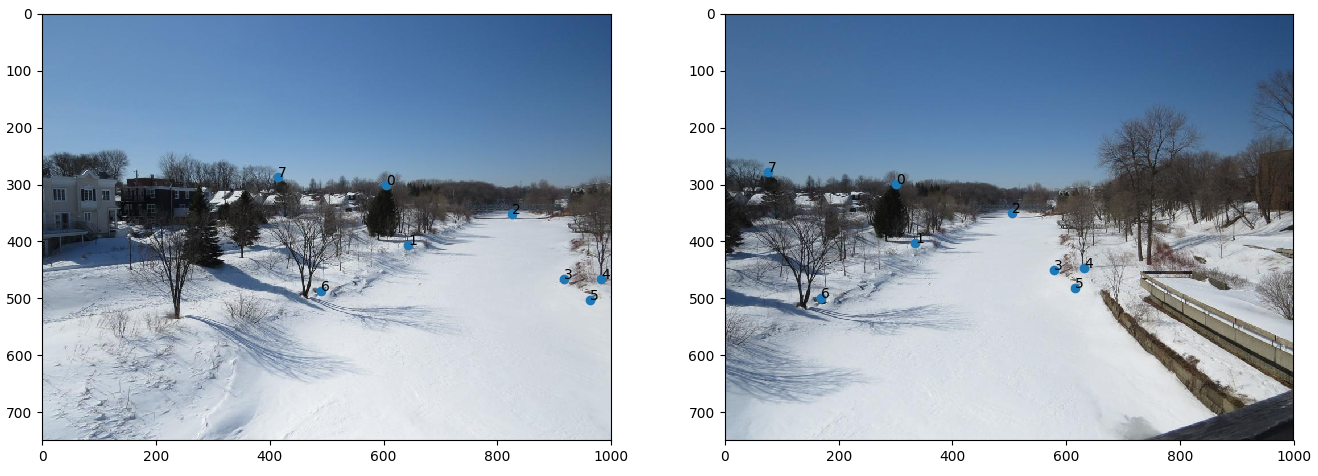 |
|---|
Comparaison IMG_2410.JPG IMG_2411.JPG 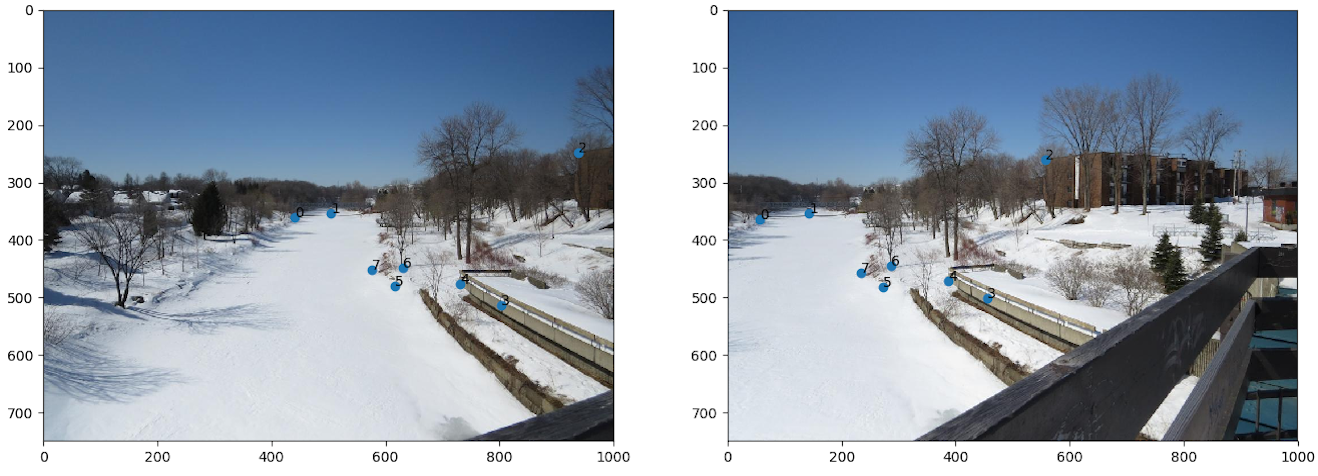 |
 Discussion : Ici encore, le résultat est très appréciable. Les points sont plus faciles à choisir entre les photos
Discussion : Ici encore, le résultat est très appréciable. Les points sont plus faciles à choisir entre les photos IMG_2410.JPG IMG_2411.JPG puisque les photos contiennent des textures plus différentes entre elles. Ainsi, peut-être que cela explique le plus grand flou dans l'assemblage des deux autres images (gauche). Sinon, nous voyons un spectre de la rembarde dans le bas de l'image. Sûrement que ce défaut vient de l'accentutation de l'erreur de lentille en bordure de l'image.
Partie 2: Appariement automatique
Dans cette partie, nous rajoutons encore une étape. En plus de trouver les homographies, il faut trouver les points de correspondance automatiquement. Pour détecter les points, nous suivons certaines étapes de l'article Multi-Image Matching using Multi-Scale Oriented Patches.
Les étapes de l'algorithme de détection et de description des points sont :
Utiliser le détecteur de Harris simple implémenté dans le fichier
code/harris.py. Les points détectés dans l'image de gauche sont les points rouges dans l'image de doite :Image d'entrée Points avec détecteur de Harris naïf 
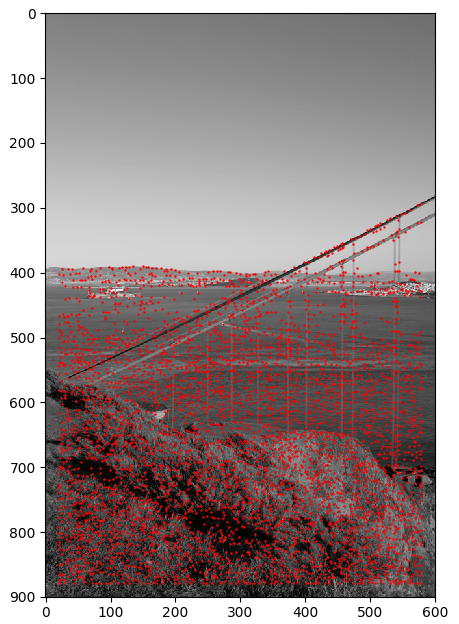
Utiliser l'Adaprative Non-Maximal Suppression (ANMS) décrit dans l'article pour obtenir de meilleurs points de correspondance. L'ANMS permet de maximiser la distance entre les points d'importances et ainsi choisir des maximums locaux.
Pour chaque point, nous calculons la distance du point plus fort le plus proche. Les points plus fort se calculent comme ceci :
Où contient les indices des points plus fort pour le point , est un facteur pour contrôler la force nécessaire pour qu'un point soit plus fort (vaut 0.9 dans le TP, comme conseillé par l'article), sont les valeurs de la matrice du détecteur de Harris pour les points à filtrer. est la valeur du point courant.
Nous gardons la distance du point plus fort le plus proche :
Nous choisissons les qui ont la distance minimale la plus grande. L'article conseille et c'est ce qui est utilisé dans l'article.
Points avec détecteur de Harris naïf Points après ANMS 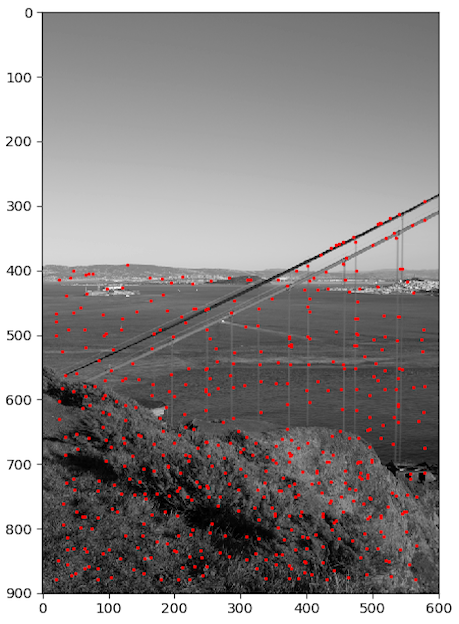
Finalement, nous construisons un descripteur pour chaque point. Nous prenons une zone de 40x40 pixels autours du point d'intérêt que nous séparons en 8x8 super-pixels constituant la moyenne d'une zone 5x5 vrais pixels. Nous obtenons ainsi un descripteur de 64 dimensions, invariant à la position seulement, ce qui fait amplement le travail pour notre problème.
Ensuite, il faut apparier les points ainsi que calculer l'homographie entre deux images. Les étapes sont les suivantes :
Nous utilisons un K-Nearest-Neighbors (K-NN) de scikit-learn afin d'apparier un point de la première image à un point de la deuxième image. Nous utilisons déjà une méthode de filtrage utilisée largement dans la littérature (voir la figure 6 de l'article) pour enlever de potentielles mauvaises correspondances avant de trouver l'homographie. Pour ce faire, nous utilisons un 2-NN et nous gardons les correspondances qui respectent le ratio suivant :
où est le ratio à respecter. Nous avons choisi celui conseillé dans la littérature et qui est en accord avec la figure 6 de l'article, c'est-à-dire . Cela permet d'avoir de s'assurer que le point se distingue bien des autres et qu'il ne consistue pas seulement un point générique.
Ensuite, en partant de ces points, nous utilisons l'algorithme de RANSAC afin de trouver l'homographie de l'image.
- Nous prenons un
échantillon de 4 correspondancesà chaque itération, 4 points tout juste nécessaires pour trouver une homographie. - Nous trouvons une homographie avec ces points et nous calculons le nombre de correspondances que l'homographie permet de bien tranformer dans un
rayon d'erreur de 3 pixels. - Nous utilisons
N itérations(variable, précisé dans la partie résultat) et à la fin de ces itérations, nous retournons l'homographie calculée à partir de tous les inliers de la meilleure solution.
- Nous prenons un
Pour assembler les images, nous utilisons un algorithme automatique également. Les étapes de l'algorithme d'assemblage sont :
Constuction d'une matrice de similitude entre images. La similitude entre une image et une image est calculée comme étant le ratio du nombre maximal d'inliers sur le nombre total de correspondance entre les images :
L'image de reprojection est choisie comme étant l'image avec la plus grande similitude :
Ensuite, nous calculons la matrice qui est la matrice de similude rectifiée. Le seuil est arbitraire, mais a démontré de bons résultats :
Nous assemblons les images en suivant un chemin naïf déterminé par la matrice :
- Nous partons de l'image de reprojection et allons vers une des images similaires notée par un 1 dans .
- Nous prenons soin de mettre la colonne de l'indice de l'image visité à 0 et gardons une pile enregistrant le mouvement pour pouvoir revenir sur nos pas.
- Nous assemblons l'image visitée sur l'image de reprojection en appliquant l'homographie nécessaire.
- Nous avançons maintenant à la prochaine image en suivant de nouveau l'étape 2. Or, cette fois, nous appliquons toutes les homographies nécessaires pour se rendre jusqu'à l'image de reproduction. Il est facile de savoir quelle homographie utilisée grâce à la pile de mouvements. Il faut également ajouter (translation) la nouvelle référence du panorama.
- Lorsque nous arrivons à une image cul-de-sac, tous des 0 sur la ligne de l'image, nous reculons dans la pile et retournons à l'étape 4.
- Lorsque toutes les images ont été visitées, que des 0 sur , nous avons fini et pouvons retourner le panorama.
Résultat avec les scènes fournies
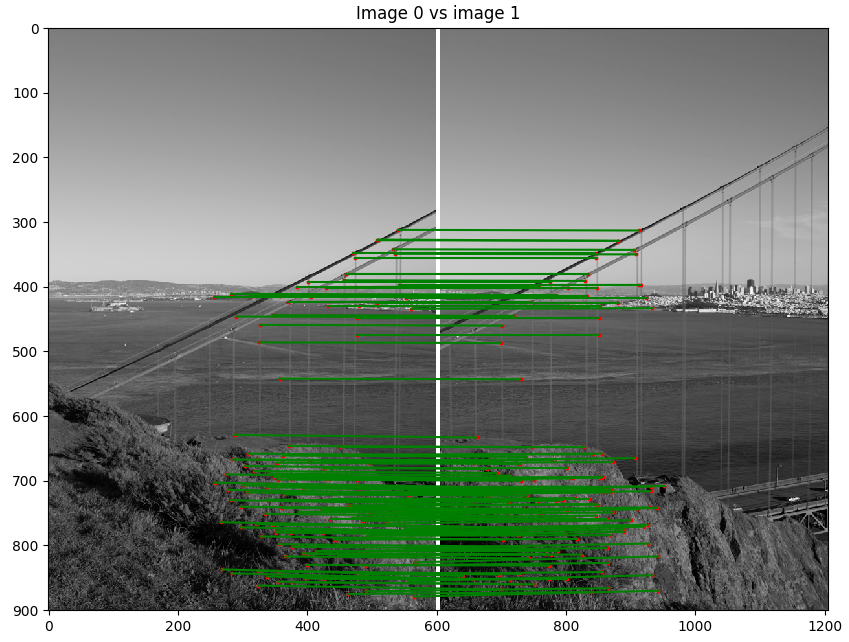
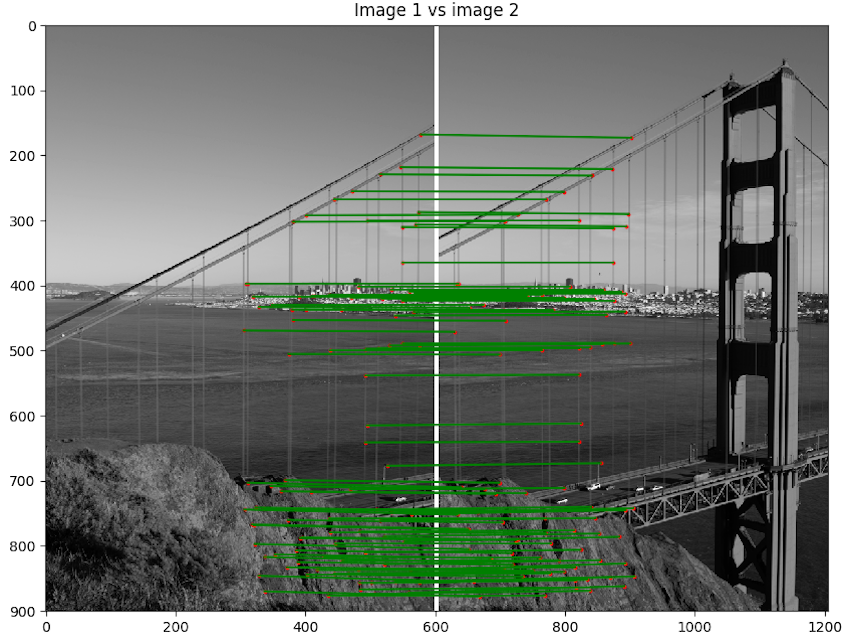
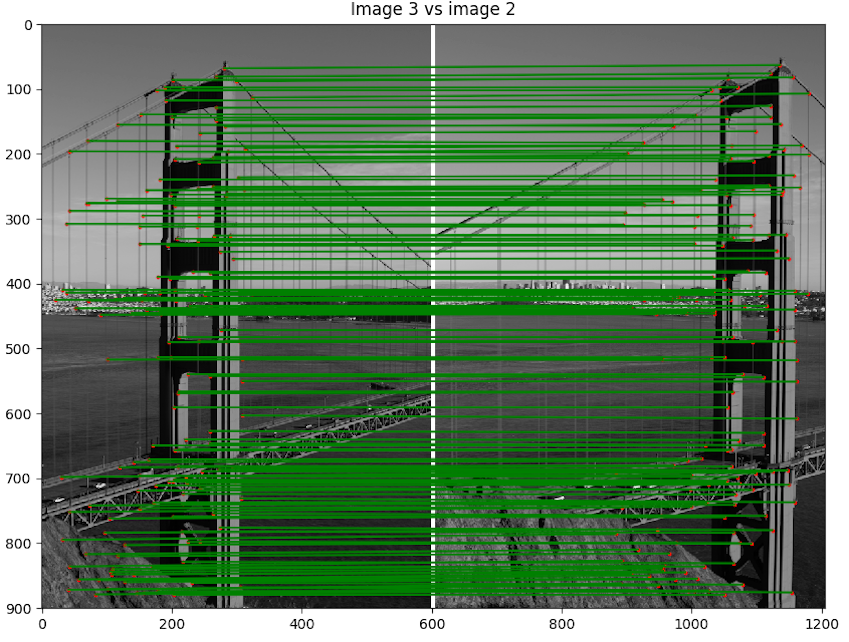
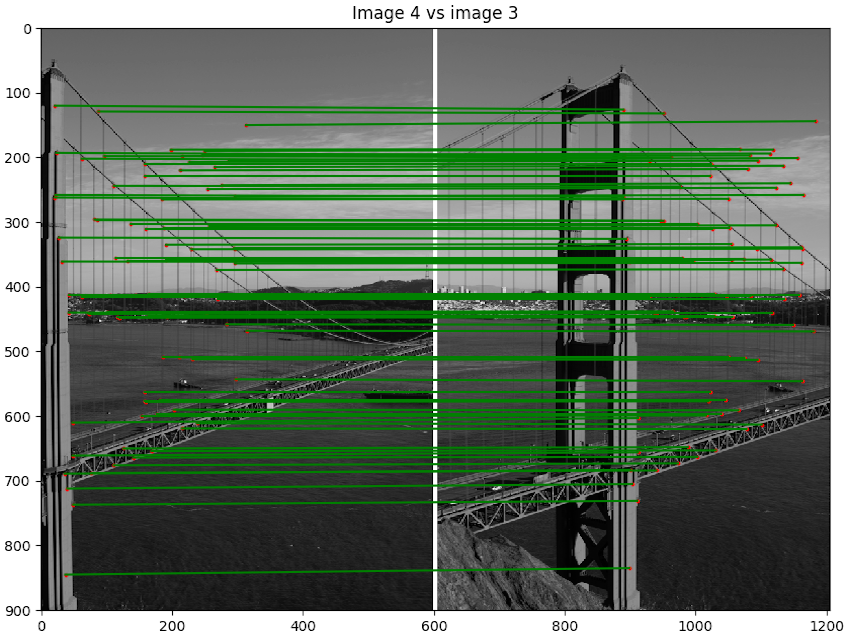
- Scène 1 : Golden Gate
- Implémentation du morphage :
code/n2.py - Commande :
python code/n2.py 1 - Image de reprojection : 2
- Itération de RANSAC : 3000
 |
|---|
 |
 |
 |
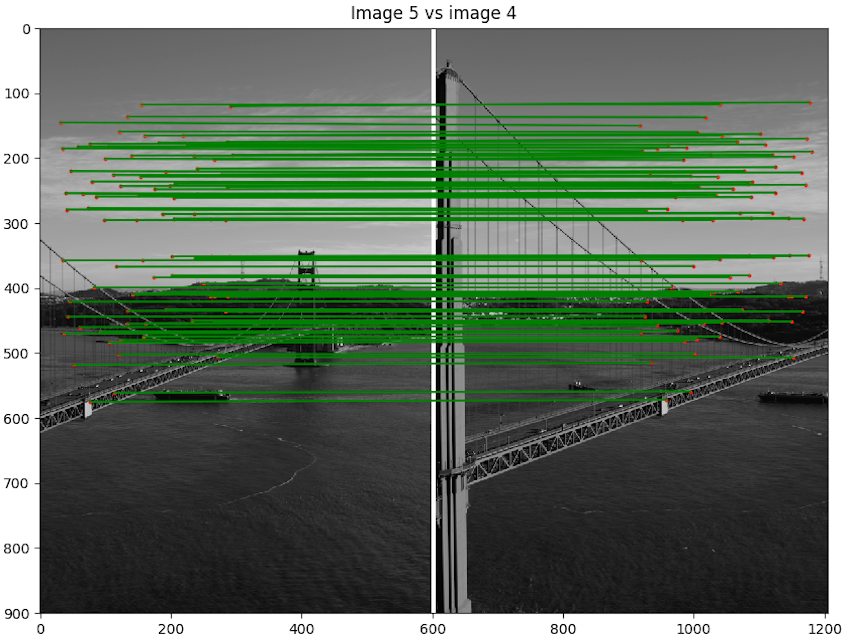 |

Discussion : Ici le résultat est vraiment impressionnant. Non seulement, nous pouvons voir que notre algorithme a bien assemblé l'image, mais il nous ne voyons pas de discontinuité près des bordures des images. Cela provient du fait que notre jeu de donnée a été préalablement traité par ceux qui l'ont créé pour enlever les défauts de lentille. Nous pouvons voir que les points choisis sont intéressants et contiennent que des inliers.
- Scène 2 : Rivière St-Charles 1
- Implémentation du morphage :
code/n2.py - Commande :
python code/n2.py 2 - Image de reprojection : 1
- Itération de RANSAC : 10000
 |
|---|
 |
 |

Discussion : Le résultat est encore statisfaisant, mais nous pouvons voir une certaine explosion de l'image de droite puisque le panorama a un champs de vue débalancé à droite. Comparativement au panorama de la même scène en partie 1, nous pouvons voir que l'algorithme automatique est beaucoup plus robuste, puisque le centre est moins flou. Or, il a fallu plus d'itérations de RANSAC pour trouver des bonnes homographie.
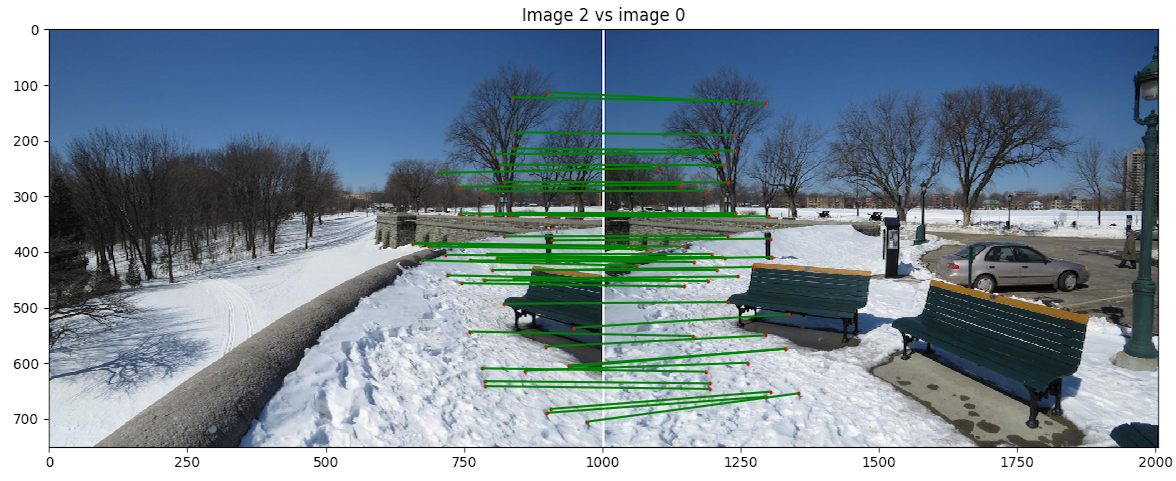
- Scène 3 : Plaine d'Abraham 2
- Implémentation du morphage :
code/n2.py - Commande :
python code/n2.py 3 4 - Image de reprojection : 4
- Itération de RANSAC : 10000
 |
|---|
 |
 |
 |
 |

Discussion : Nous obtenons encore un bon résultat malgré le léger flou dans les arbres à gauche. Le résultat est impressionnant puisque les images ont été prises sur l'axe des x et sur l'axe des y et le résultat est tout de même impécable.
Résultat avec nos scènes
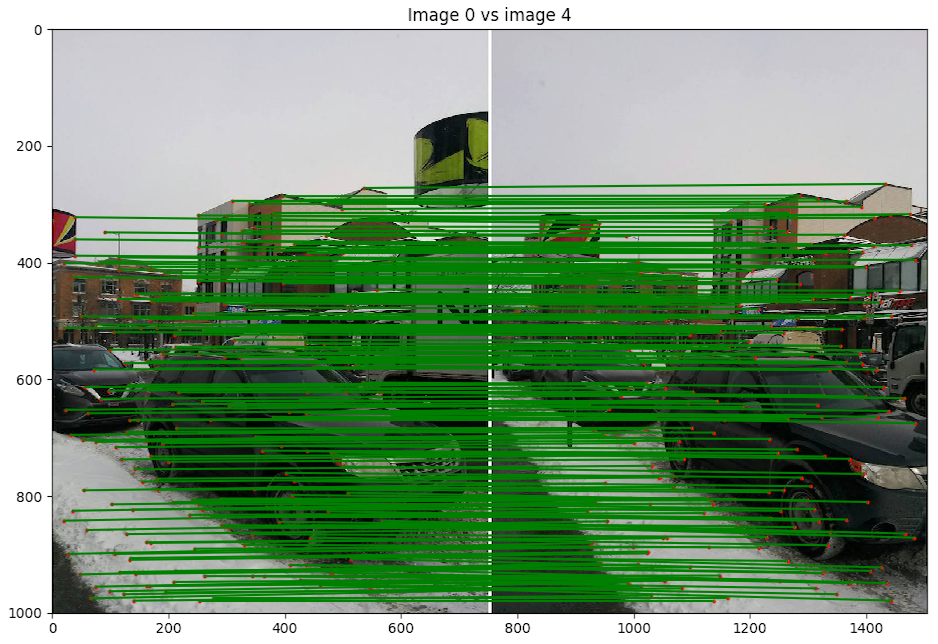
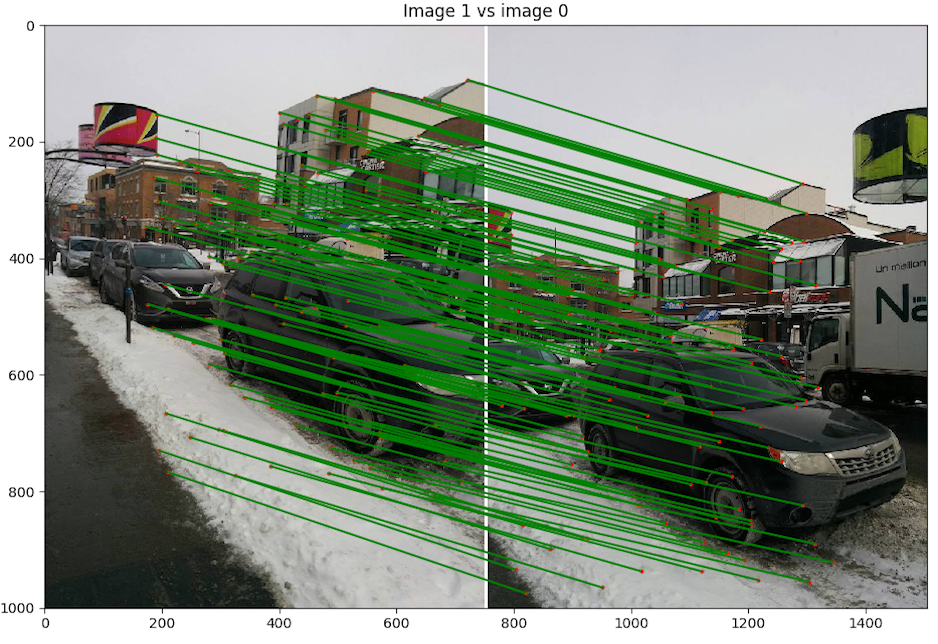
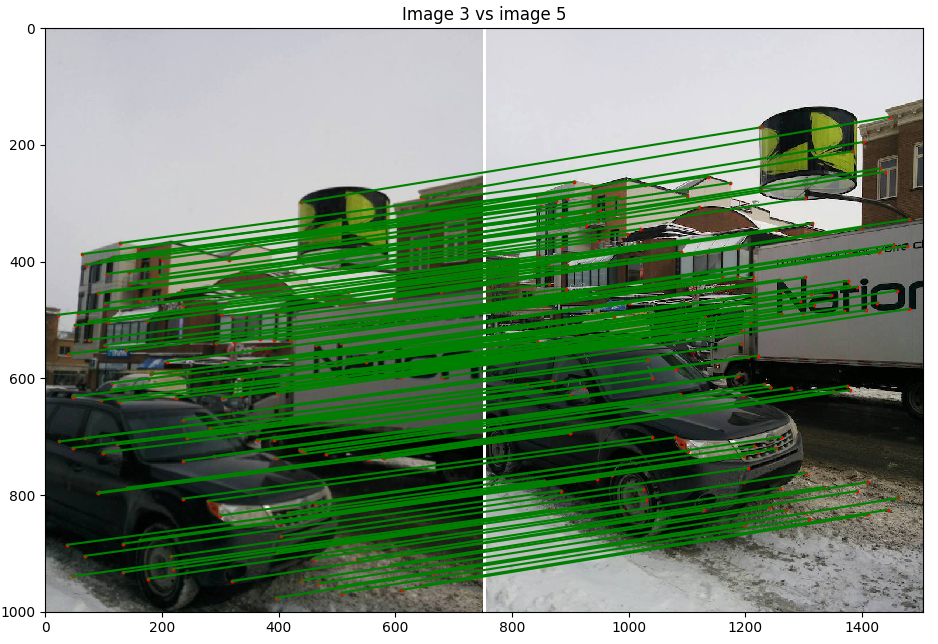
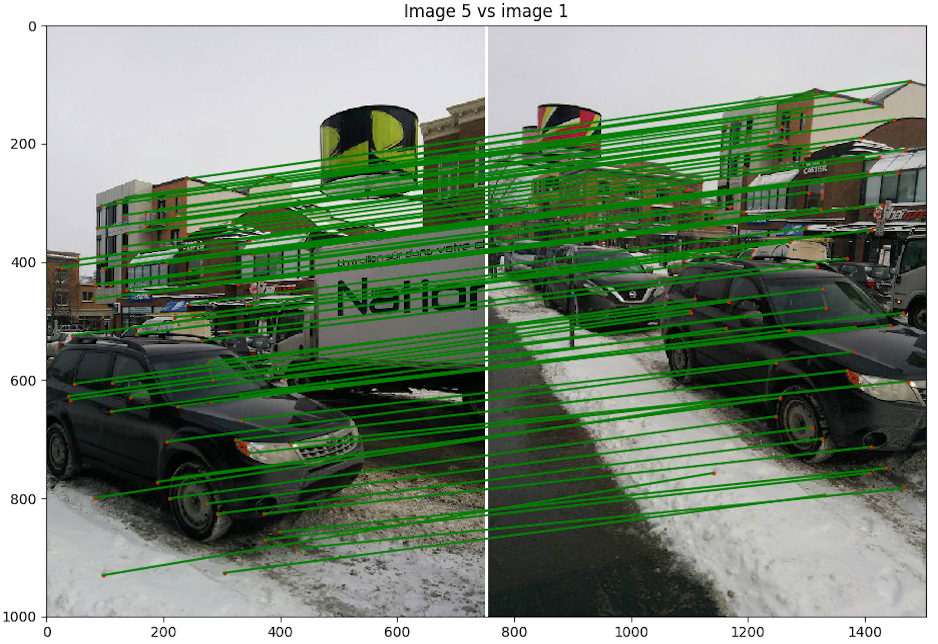
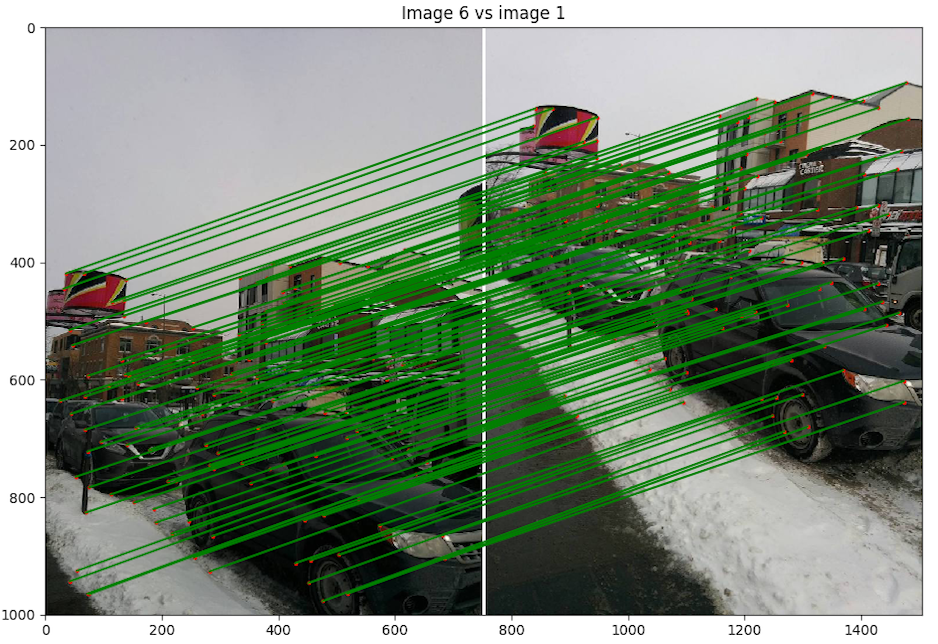
- Scène 2 : Rue Cartier, photo de Nexus 5
- Implémentation du morphage :
code/n2.py - Commande :
python code/n3.py 1 - Image de reprojection : 4
- Itération de RANSAC : 10000
 |
|---|
 |
 |
 |
 |
 |
 |

Discussion : Nous pouvons voir l'effet de la balance des blancs du cellulaire et qui change la luminosité des images et ainsi crée des discontinuités dans le panorama. Malgré cela, le résultat est très bon, les images sont bien alignées pour des images prises avec un cellulaire avec un centre de projection un peu instable entre les images. Nous avons fait exprès de prendre des photos sur l'axe des x et l'axe des y pour voir si cela allait rendre la tache plus difficile à notre algorithme, mais il réussit à créer un bon panorama.
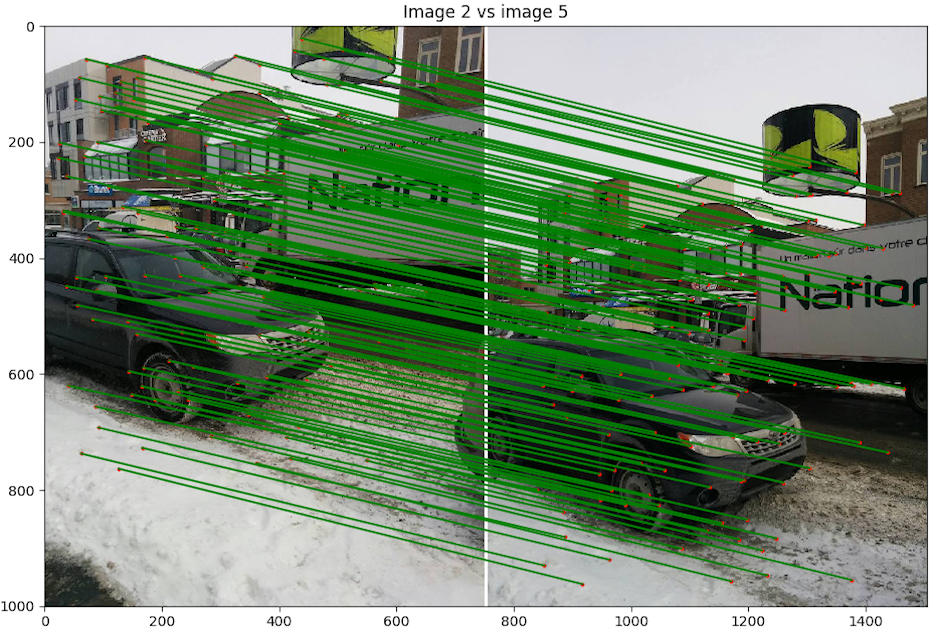
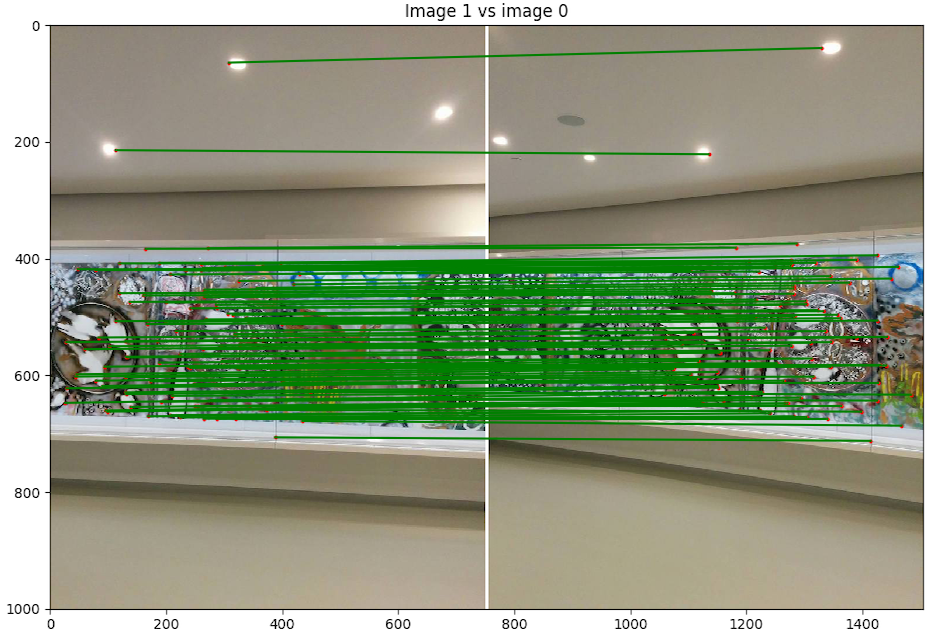
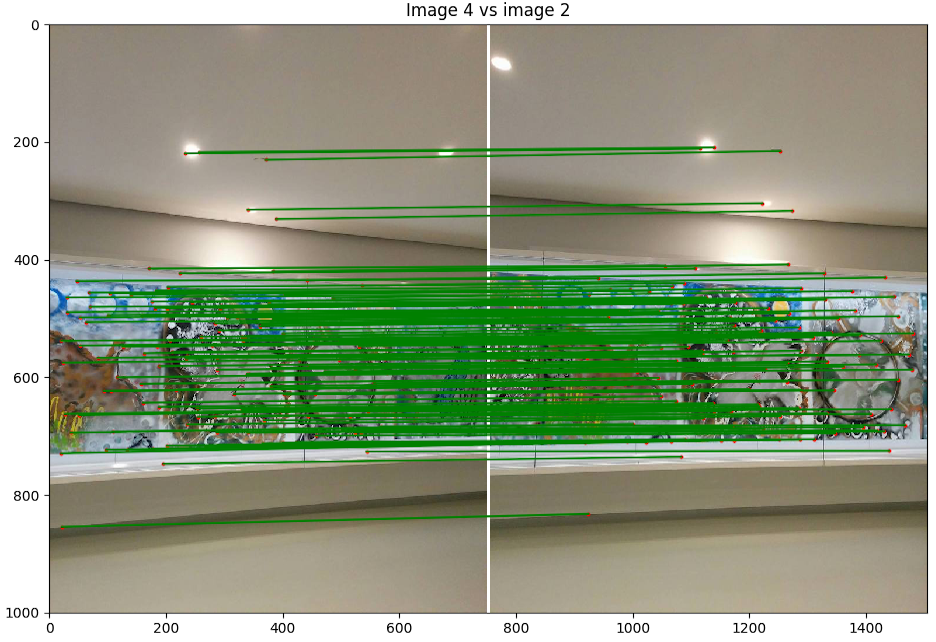
- Scène 2 : Riopelle du musée, photo de Nexus 5
- Implémentation du morphage :
code/n2.py - Commande :
python code/n3.py 2 - Image de reprojection : 3
- Itération de RANSAC : 10000
 |
|---|
 |
 |
 |
 |
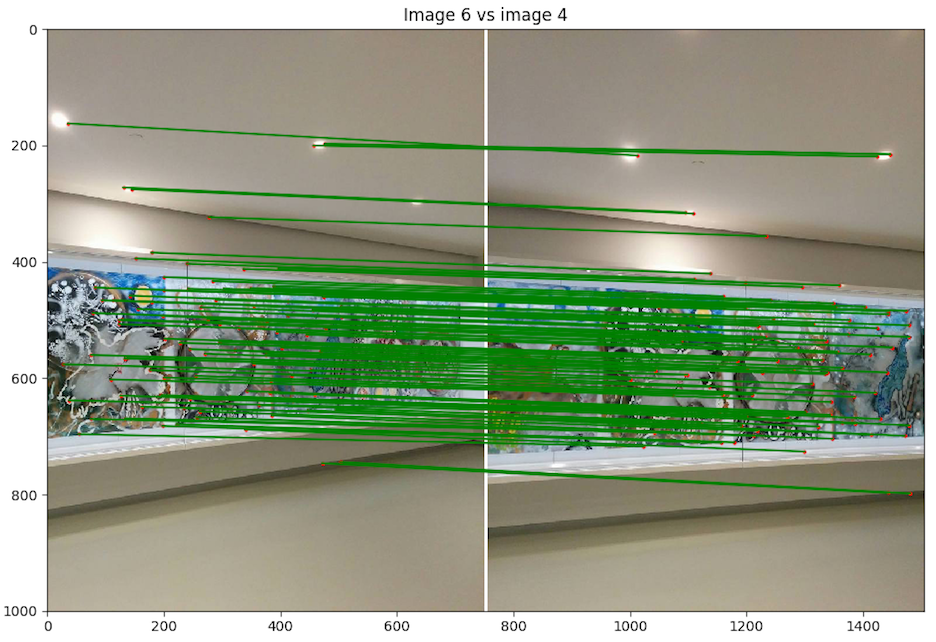 |

Discussion : Nous avons décidé de faire un panorama classique pour la fin avec la célèbre fresque de Riopelle au Musée des Beaux-Art National du Québec. Le résultat est quand même excellent pour des photos de Nexus 5 avec un centre de projection instable. Nous voyons par contre que l'instabilité a induit des erreurs à gauche où l'on peut apercevoir un flou désagréable.
Pour comparer, nous avons pris un panorama de la même scène avec l'algorithme de Google. Nous voyons que notre algorithme arrive à donner un résultat quand même intéressant malgré sa simplicité comparativement à la complexité de l'algorithme à projection cylindrique de Google. Les images ont été rognée pour les besoins de la comparaison :
| Sans Google |
|---|
 |
| Avec Google |
 |