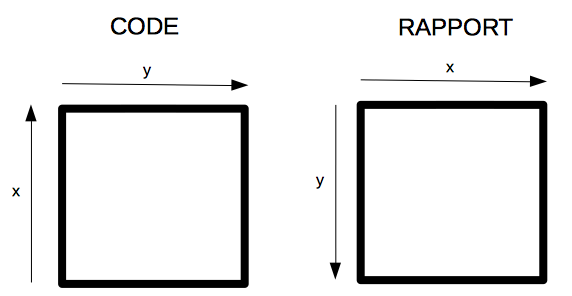
Important : Dans le rapport, pour respecter la convention habituelle en vision, y fait référence à l'hauteur de l'image et x fait référence à la largeur de l'image. Or, dans le code, x sert à indexer l'hauteur de l'image tandis que y sert à indexer la largeur de l'image. Suivre cette convention:
Dans cette section, il fallait colorier neuf images en noir et blanc prises par Prokudin-Gorskii au début du XXe siècle.
Pour ce faire, nous avons les scans des plaques de verre de ces vieilles photos prises chacune sous l'influence d'un filtre rouge, vert et bleu. Ainsi, en combinant les trois composantes, nous pouvons obtenir l'image en couleur de la photo de l'époque.
Par contre, il est important de bien aligner les différentes composantes avant de reconstituer l'image à 3 canaux. Le canal rouge est pris comme image de référence, sur lequel on aligne le canal vert et finalement le canal bleu.
Deux métriques ont été implémentées pour calculer l'erreur d'alignement. Premièrement, la norme L2 et la corrélation croisée normalisée (CCN). Or, puisque la CCN donne sensiblement les mêmes résultats que la norme L2 pour un temps d'exécution plus long, nous montrerons que les résultats obtenus avec la norme L2.
Pour toujours calculer les métriques sur le chevauchement des images et pour enlever les bordures, nous coupons les images avec la plus petite zone possible lors des translations. Par exemple, avec [-15,15], nous enlevons 15px de chacune des 4 bordures.
Processeur utilisé : i5-4690k 3.5Ghz
code/colorizer.pycode/no1.py
 00106v.jpg
00106v.jpg
|
 00757v.jpg
00757v.jpg
|
 00888v.jpg
00888v.jpg
|
 00889v.jpg 00889v.jpg |
 00907v.jpg 00907v.jpg |
 00911v.jpg 00911v.jpg |
 01031v.jpg 01031v.jpg |
 01657v.jpg 01657v.jpg |
 01880v.jpg 01880v.jpg |
| translation canal vert | translation canal bleu | |
|---|---|---|
| 00106v.jpg | y = 5 ~ x = 2 | y = 9 ~ x = 1 |
| 00757v.jpg | y = 3 ~ x = 2 | y = 5 ~ x = -5 |
| 00888v.jpg | y = 6 ~ x = 0 | y = 12 ~ x = 0 |
| 00889v.jpg | y = 3 ~ x = -1 | y = 4 ~ x = -3 |
| 00907v.jpg | y = 3 ~ x = 1 | y = 6 ~ x = 0 |
| 00911v.jpg | y = 12 ~ x = 1 | y = 13 ~ x = 1 |
| 01031v.jpg | y = 3 ~ x = 0 | y = 4 ~ x = -2 |
| 01657v.jpg | y = 6 ~ x = 0 | y = 12 ~ x = -1 |
| 01880v.jpg | y = 8 ~ x = -2 | y = 14 ~ x = -4 |
En partie 2, le problème était sensiblement le même qu'en 1, sauf que cette fois-ci, nous devions faire les tests sur des images .tif à haute résolution. Ainsi, la recherche exaustive de la partie 1 n'est plus soutenable puisqu'elle devient beaucoup trop longue. Nous avions 9 images initiales à traiter, plus 12 images choisies du net.
La solution utilisée était de faire une recherche en pyramide d'image. Ainsi, il est possible de faire une recherche sur un intervalle énorme, [-200,200] par exemple, en faisant les translations dans une échelle plus basse tout en raffinant l'alignement à chaque niveau. Chaque niveau d'échelle est 2 fois plus petit que son niveau parent.
Par exemple, si nous utilisons un intervalle [-200,200] et 4 niveaux d'échelle, puisque le plus bas niveau est 4 fois plus petit, l'intervalle y sera de [-25,25]. En remontant au niveau supérieur, nous appliquons la translation trouvée au niveau inférieur fois un facteur de 2. À ce niveau, nous divisons l'intervalle précédent d'un facteur 2 puisque nous avons déjà fait une partie du travail au niveau inférieur. L'intervalle de recherche y est donc de : [-12, 12]. Nous continuons ainsi de suite jusqu'au plus haut niveau.
Ici également, pour toujours calculer les métriques sur le chevvauchement des images et pour enlever les bordures, nous coupons les images avec la plus petite zone possible lors des translations. Par exemple, avec [-200,200], nous enlevons 200px de chacune des 4 bordures.
Processeur utilisé : i5-4690k 3.5Ghz
code/colorizer.pycode/no2.py 00029u.tif 00029u.tif |
 00087u.tif 00087u.tif |
 00128u.tif 00128u.tif |
 00458v.tif 00458v.tif |
 00737v.tif 00737v.tif |
 00822v.tif 00822v.tif |
 00892v.tif 00892v.tif |
 01043v.tif 01043v.tif |
 01047v.tif 01047v.tif |
 00169v.tif 00169v.tif |
 00188v.tif 00188v.tif |
 00792v.tif 00792v.tif |
 00836v.tif 00836v.tif |
 00878v.tif 00878v.tif |
 00925v.tif 00925v.tif |
 01018v.tif 01018v.tif |
 01084v.tif 01084v.tif |
 01125v.tif 01125v.tif |
 01329v.tif 01329v.tif |
 01539v.tif 01539v.tif |
 01640v.tif 01640v.tif |
| translation canal vert | translation canal bleu | |
|---|---|---|
| 00029v.tif | y = 59 ~ x = -19 | y = 92 ~ x = -33 |
| 00087v.tif | y = 59 ~ x = -14 | y = 107 ~ x = -55 |
| 00128v.tif | y = 17 ~ x = -13 | y = 52 ~ x = -37 |
| 00458v.tif | y = 43 ~ x = -27 | y = 87 ~ x = -32 |
| 00737v.tif | y = 34 ~ x = -8 | y = 49 ~ x = -14 |
| 00822v.tif | y = 68 ~ x = -8 | y = 125 ~ x = -32 |
| 00892v.tif | y = 27 ~ x = -1 | y = 43 ~ x = -4 |
| 01043v.tif | y = 26 ~ x = -8 | y = 10 ~ x = -17 |
| 01047v.tif | y = 47 ~ x = -14 | y = 71 ~ x = -33 |
| translation canal vert | translation canal bleu | |
|---|---|---|
| 00169v.tif | y = 39 ~ x = 27 | y = 114 ~ x = 68 |
| 00188v.tif | y = 77 ~ x = 7 | y = 75 ~ x = 9 |
| 00792v.tif | y = 88 ~ x = 6 | y = 161 ~ x = -1 |
| 00836v.tif | y = 64 ~ x = 9 | y = 101 ~ x = 20 |
| 00878v.tif | y = 19 ~ x = 6 | y = 28 ~ x = 2 |
| 00925v.tif | y = 33 ~ x = -27 | y = 61 ~ x = 60 |
| 01018v.tif | y = 48 ~ x = -9 | y = 82 ~ x = -26 |
| 01084v.tif | y = 77 ~ x = -18 | y = 142 ~ x = -30 |
| 01125v.tif | y = 49 ~ x = 15 | y = 88 ~ x = 14 |
| 01329v.tif | y = 51 ~ x = -2 | y = 99 ~ x = -23 |
| 01539v.tif | y = 51 ~ x = 5 | y = 95 ~ x = -3 |
| 01640v.tif | y = 102 ~ x = 7 | y = 155 ~ x = 16 |
Dans la troisième partie, il fallait se mettre dans la peau de Prokudin-Gorskii en prenant nos propres photos. Pour ce faire, nous prenons 3 photos d'une scène en essayant de bouger le moins possible. Ensuite, nous prenons le canal bleu de la première image, le canal vert de la 2e image et le canal rouge de la troisième image pour simuler une paque de verre de Prokudin-Gorskii.
Toute les photos ont été prises avec un Nexus 5. Les photos sont en jpeg et sont de taille 1314×1776. Nous avons pris 5 scènes.
code/colorizer.pycode/no3.py mycolor1.jpg mycolor1.jpg |
 mycolor2.jpg mycolor2.jpg |
 mycolor3.jpg mycolor3.jpg |
 mycolor4.jpg mycolor4.jpg |
 mycolor5.jpg mycolor5.jpg |
| translation canal vert | translation canal bleu | |
|---|---|---|
| mycolor1.jpg | y = 11 ~ x = 13 | y = 7 ~ x = 14 |
| mycolor2.jpg | y = -3 ~ x = 20 | y = -10 ~ x = 7 |
| mycolor3.jpg | y = 8 ~ x = -2 | y = 22 ~ x = -14 |
| mycolor4.jpg | y = -18 ~ x = -12 | y = 16 ~ x = 1 |
| mycolor5.jpg | y = -18 ~ x = -35 | y = -1 ~ x = -16 |
Les deux premières images (mycolor1.jpg, mycolor2.jpg) ont été prises avec de bonnes conditions de stabilité. Nous voyons que, dans ce cas, l'image reconstruite est très proche de l'image initiale.
Pour l'image mycolor3.jpg, nous avons fait exprès d'y inclure des éléments mobiles entre les photos pour voir l'effet sur l'image reconstruite. Nous voyons que les voitures induisent des artéfacts dans l'image en couleur. Nous voyons le spectre de la voiture dans le canal sélectionné.
Pour les deux dernières images (mycolor4.jpg, mycolor5.jpg), les photos ont été prises avec un peu d'instabilité. L'algorithme a donc plus de difficulté à trouver le bon aligment et nous pouvons voir des artéfacts sur les contours des objets.
Nous avons essayé d'améliorer la qualité de l'image en faisant une égalisation d'histogramme sur chaque canal.
code/colorizer.py (fonction doAjdustConstrast=True)code/bonus.py 00106v.jpg 00106v.jpg |
 00757v.jpg 00757v.jpg |
 00888v.jpg 00888v.jpg |
 00889v.jpg 00889v.jpg |
 00907v.jpg 00907v.jpg |
 00911v.jpg 00911v.jpg |
 01031v.jpg 01031v.jpg |
 01657v.jpg 01657v.jpg |
 01880v.jpg 01880v.jpg |