Cet article démontre une approche de reconnaissance d'objet ou de scène grâce à l'utilisation de mot visuel. Cette approche consiste à créer des mots visuels avec des descripteurs, en faire un dictionnaire et donc utiliser cela pour faire la reconnaissance des scènes ou des objets.
Pour démarrer le code tout simplement partir le script Main. Après avoir fait la construction du dictionnaire, le programme va demander de choisir l'objet dans les images de recherche. L'objet est choisi en cliquant deux points dans l'image. Par exemple choisir la caméra. De plus, il y a des scripts de vérification pour regarder les données. VérificationClosest affiche les 3 meilleures images choisies pour chacune des images de recherche. VérificationHisto affiche l'histogramme du dictionnaire. VérificationWords affiche un mot en particulier dans le dictionnaire. n étant l'index du mot.
Trois data sets ont été utilisés pour les expérimentations. Le premier (freiburg) est contient des photos en continu d'un bureau. Le deuxième (trajectoire) contient les photos en continu de la trajectoire d'un robot. Ceux-ci sont bons pour tester'algorithme sur des vidéos et donc les mots visuels risque d'être plus répartie. Le troisième (Tokyo) contient des photos de scène dans la ville de Tokyo.Chaque scène est photographiée à des temps différents de la journée. Celui-ci va tester l'algorithme sur des photos non continues et les mots visuels seront moins répartis.
Le dossier code contient aussi des données déjà calculées pour la vérification
La construction du dictionnaire commence avec la détection des points d'intérêt dans les photos du vidéo. Cette détection est faite grâce à l'algorithme de Harris.Ensuite, on extrait les descripteurs de ces points. Les descripteurs sont ensuite comparés entre eux pour les regrouper dans des mots visuels. La construction du dictionnaire est déterminée par plusieurs paramètres. La résolution des images détermine le nombre de points d'intérêt trouvés. Le nombre de points conserver change le nombre de descripteur par image. La dimension des descripteurs détermine l'information dans chaque descripteur, ce qui augmente la précision de la comparaison. Finalement, la distance maximale entre les descripteurs détermine la similitude qu'il fait pour que les descripteurs soient dans un group. La fonction de comparaison entre les descripteurs suggérer par l'article est celle-ci , mais après plusieurs expérimentations la fonction corr2 de Matlab à présenté de meilleurs résultats.
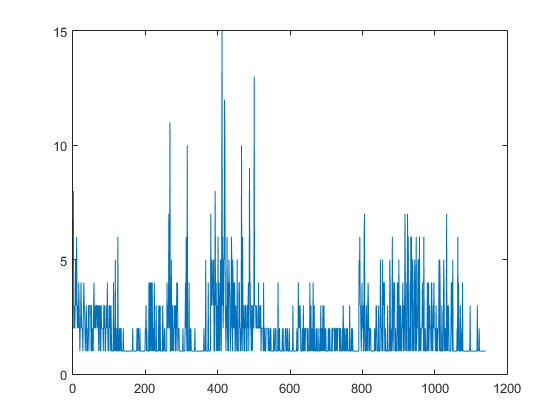
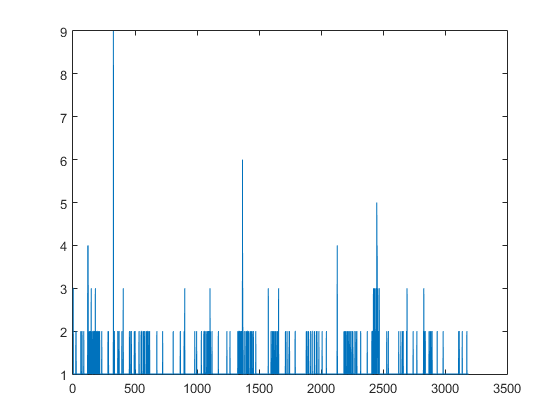
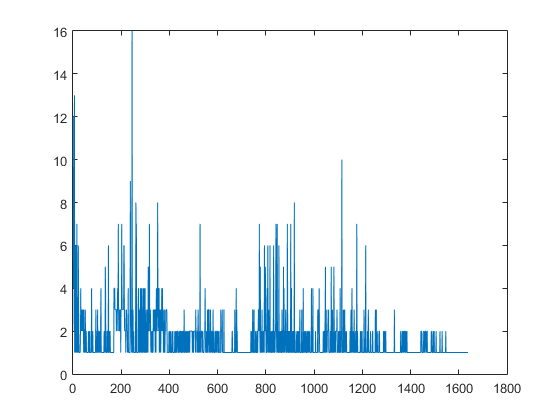
On peut voir la distribution des mots grâce à un histogramme.
Ensuite pour chaque image, on calcule l'histogramme de chaque image. Ces histogrammes vont être utilisés pour la comparaison avec des nouvelles images. Les nouvelles images sont donc analysées de la même manière pour obtenir un histogramme des mots visuels dans le dictionnaire. Les histogrammes des nouvelles images sont donc comparés à ceux utilisés pour la construction du dictionnaire.
Les bons choix faits par l'algorithme sont mis en gras..
Voici plusieurs exemples pour la reconnaissance de scène.
Il est aussi possible d'utiliser l'algorithme pour détecter des objets en choisissant la région de l'objet dans l'image et en ne prenant que les descripteurs de cette région. On construit l'histogramme et on compare pour trouver la scène.
Voici plusieurs exemples pour la reconnaissance d'objet.
On peut voir que pour ce qui est de la détection de la scène, l'algorithme marche sans problème et ne rencontre pas vraiment de difficulté si les photos sont en contenus. Par contre, lors de la détection d'objet on peut voir de la difficulté.Ceci vient des cas où la sous-division de l'image contenant l'objet ne contient pas beaucoup de descripteurs pour obtenir un bon histogramme. Ces difficultés peuvent être aidées en augmentant le nombre de descripteurs.Soit en augmentant la résolution des images pour la construction du dictionnaire ou en prenant plusieurs sous-images de l'objet pour avoir plus d'information.
{kind=link}
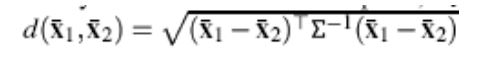{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}