TP4: Assemblage de photos
Introduction
Les panoramas étaient d'abord utilisés pour représenter une grande scène grâce à plusieurs photos. Maintenant, on peut utiliser ces algorithmes pour la recherche en photographie algorithmique. Ce travail est divisé en trois sections. La première consiste en la conception d'un algorithme de panorama manuel en sélectionnant manuellement des points d'intérêts dans deux photos ayant une zone en chevauchement. Une transformation de perspective est calculée puis appliquée sur la deuxième image pour la coller dans le repère de la première image. La deuxième partie de ce travail est d'écrire un algorithme qui va faire la détection automatique des points d'intérêts dans les deux images. En effet, en exécutant le code, on obtient un panorama automatiquement sans avoir à faire des étapes manuellement. La dernière partie est d'utiliser les concepts exploités dans les algorithmes pour modiffier réalistiquement des scènes réelles ou encore de créer des scènes intéressantes.
Panorama manuel
La première étape de l'algorithme consiste à sélectionner manuellement des points d'intérêts (points où les gradients sont forts et orientés selon l'axe des X et des Y). À partir des points, on calcule une matrice de transformation (une homographie) grâce
à un système d'équation surdimensionné que l'on résoue avec une décomposition en valeur singulière (SVD). La solution du système réside dans le vecteur propre associé à la valeur propre minimale car elle minimise l'erreur du système. Maintenant que l'homographie
a été trouvée, on applique cette matrice aux coordonnées des quatre coins de l'image à transformer. Un cadre est construit pour inclure la totalité des points transformés. La zone entre les quatre coins est représentée à l'aide d'un masque binaire. Pour chaque
pixel inclu dans cette zone, on applique l'homographie inverse puis on extrapole les valeurs RGB du pixel.
Pour optimiser la détection des points d'intérêts, un algorithme positionne plus précisement les points en trouvant les translations qui minimise l'erreur quadratique entre une image du voisinage du point de l'image 1 vers l'image du voisinage du point correspondant
dans la deuxième image. Six points d'intérêt ont été sélectionnés pour créer pour coller les images.
Il est à noter que pour le troisième panorama, les photos ont été prises sans trépied ce qui peut rendre l'algorithme moins efficace car le centre de projection n'est pas a été déplacé entre les photos. De plus, puisque l'on projète les images sur un plan,
les images aux extrémités du panorama sont très étalées car les projections sont plus grandes.
|
Panorama 1 manuel: 6 photos 
|
|
Panorama 2 manuel: 7 photos 
|
|
Panorama 3 manuel: 4 photos 
|
Panorama automatique
Détection de coins avec Harris
Pour faire la détection de coins dans deux images que l'on souhaite fusionner, on utilise l'algorithme d'Harris qui nous ait disponible. Ce code donne les coordonnées des points où le gradient à une haute valeur et est orienté selon une certaine direction.
Comme on peut le voir sur l'exemple suivant, le code donne une quantité trop élevée de points d'intérêts. Les prochaines étapes permetteront de garder seulement une centaine de points pertients et présents dans les deux images.

Répression maximale non adaptative (ANMS)
Afin de ne pas avoir un regroupement de points voulant représenter le même coin, on écrit un code pour avoir une certaine distance entre des points d'intérêts. Ce code compare la distance minimale entre deux points où le poids de xi est inférieur à 90% du
poids de xj. Pour tous les poids, on conserve la distance euclidienne minimale. On garde finalement que les N points ayant le rayon le plus élevé. Dans mes résultats, je conserve 700 points après cette étape.

Comparaison des descripteurs
Afin d'associer un point de l'image 1 à son équivalent dans l'image 2, on se sert de descripteurs. Ces descripteurs sont de petites images échantillonnées de l'image contenant le point sur une fenêtre de 40x40 pixels, puis redimmensionnés en une image de
8x8 pixels. Ces images sont ensuite normalisées sur la moyenne (m=0) et sur l'écart-type (std=1). Puis, pour chaque descripteur de l'image 1, on trouve le descripteur de l'image 2 qui minimise l'erreur. Pour chaque descripteurs, on note la position des deux
descripteurs ayant l'erreur la plus faible. Par la suite, on fait le ratio des distances euclidiennes entre les coordonnées du descripteurs de l'image 1 avec le descripteur d'erreur minimale de l'image 2 par la distance du descripteur de l'image 1 avec le
deuxième descripteur d'erreur minimale de l'image 2. Dans mon cas, je conservais les appariements avec un ratio inférieur à 1.

Random Sample Consensus (RANSAC)
La dernière étape est de trouver la meilleure homographie entre les deux images. L'algorithme choisit aléatoirement 4 points dans la liste de points obtenue à l'étape précédente et calcule une homographie. L'homographie est appliquée sur le reste des coordonnées
des descripteurs. On calcule ensuite la distance entre un point de l'image 1 et son homologue transformé. On compte ensuite le nombre de paires qui on une distance inférieure à un seuil (mis à 3 pixels dans mes calculs). Puis, on répète un certain nombre de
fois (5000 fois dans mon cas). Pour l'itération ayant le plus grand nombre de points consistants, on recalcule une homographie avec ces points consistents. Cette homographie est donc la solution recherchée.
Après ces étapes, on obtient le résultat suivant. Dans cette situation, on a compté 130 points consistants.

Résultats avec le panorama automatique
Les résultats sont généralement plus précis (moins d'effet phantome dans les zones en chevauchement) mais il est plus difficile de mettre beaucoup de photos. Ce problème est probablement dû à la difficulté de l'algorithme à faire l'appariement d'un point d'une image distorsionnée avec un point d'une image non-distorsionnée.
|
Panorama 1 automatique: 4 photos 
|
|
Panorama 2 automatique: 5 photos 
|
|
Panorama 3 automatique: 4 photos 
|
Résultats sur mes images
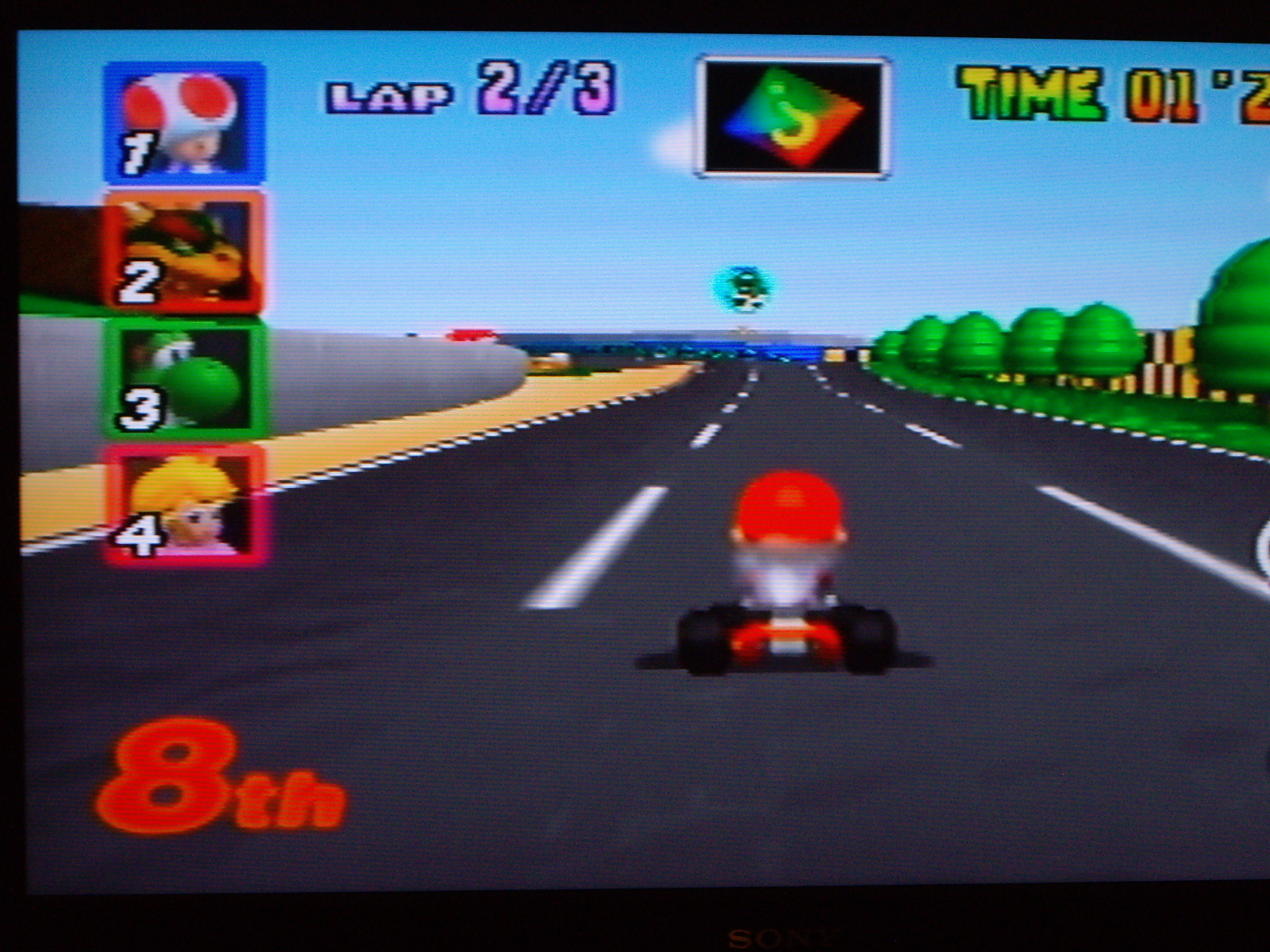
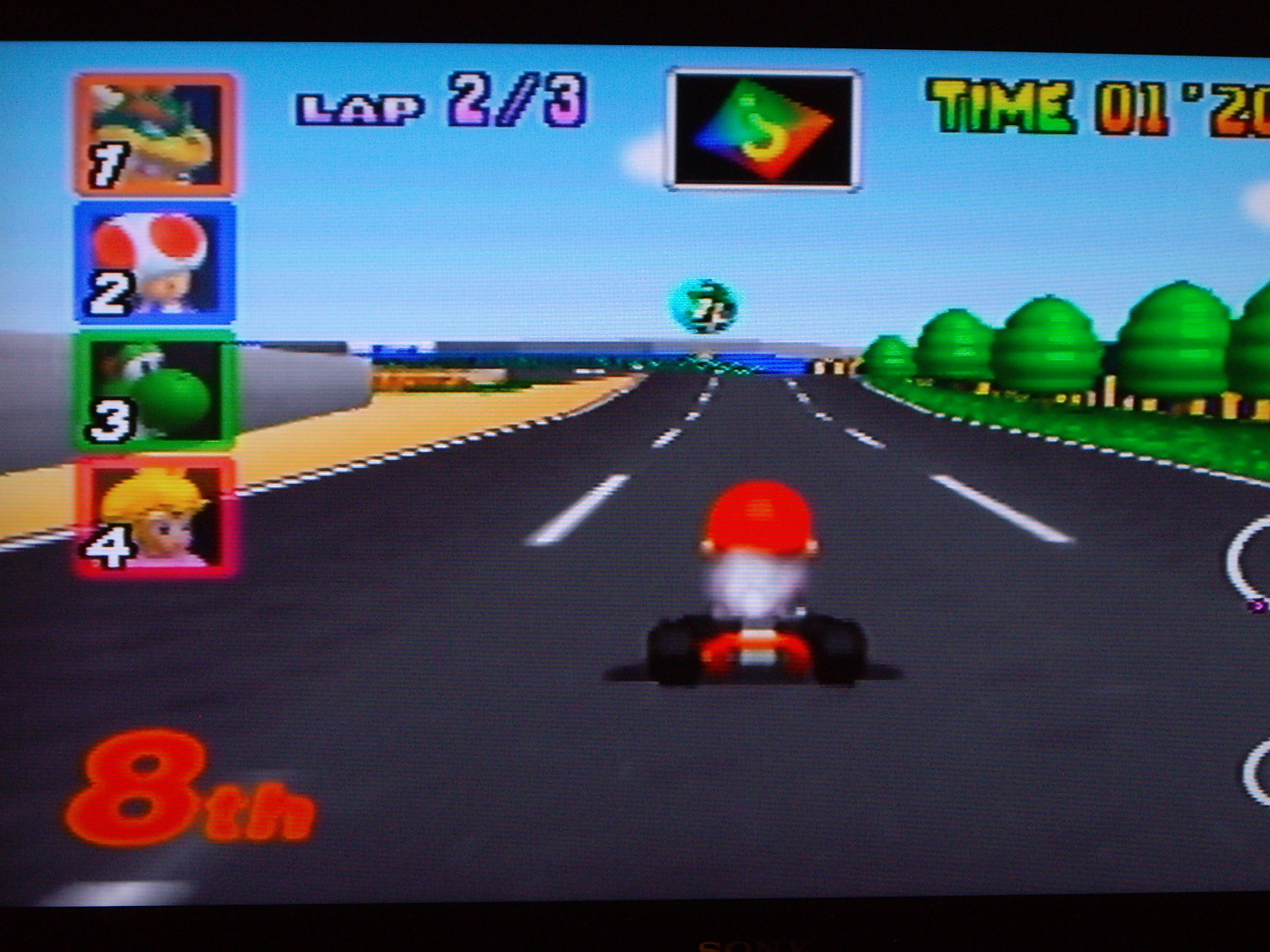
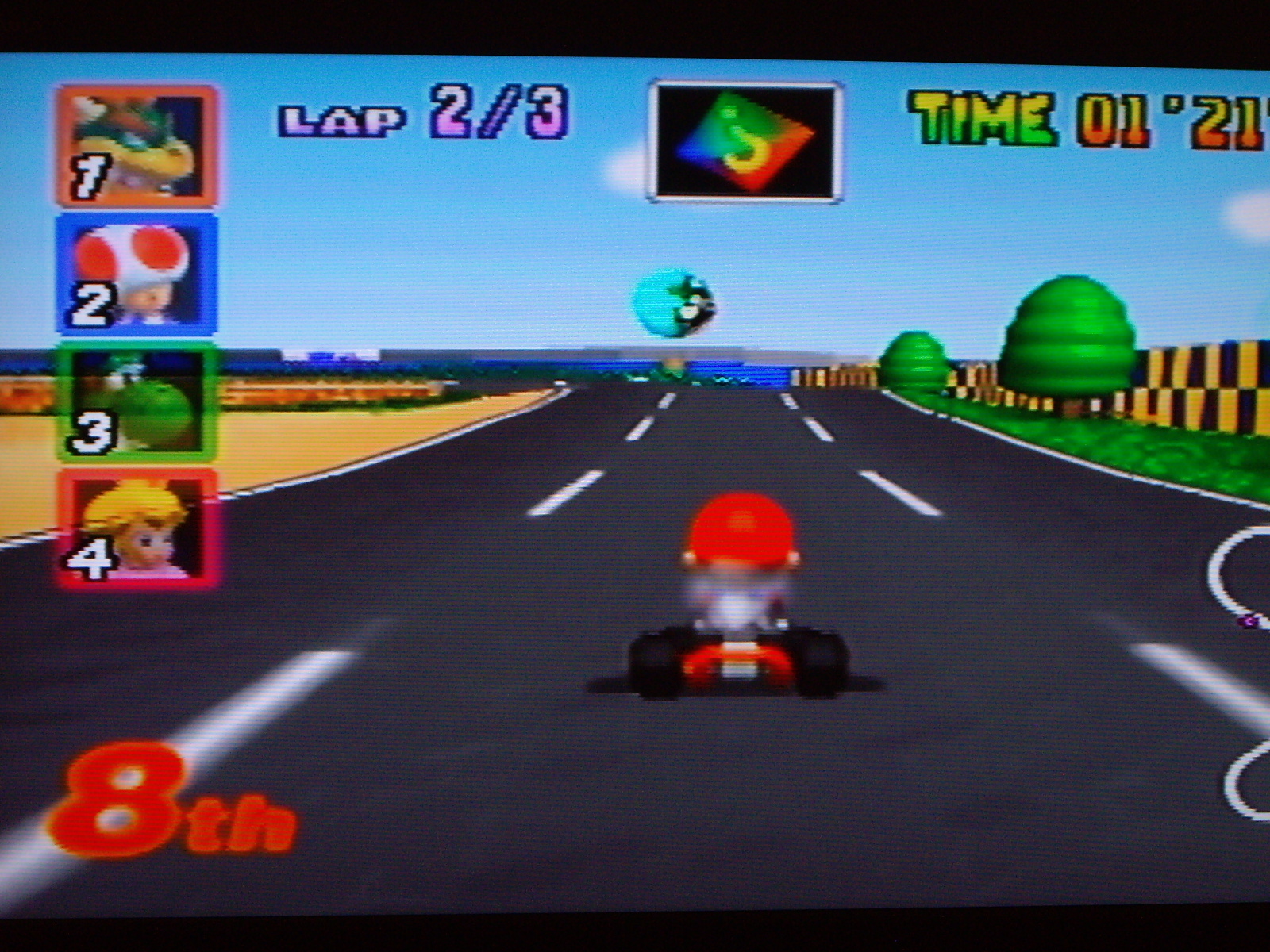
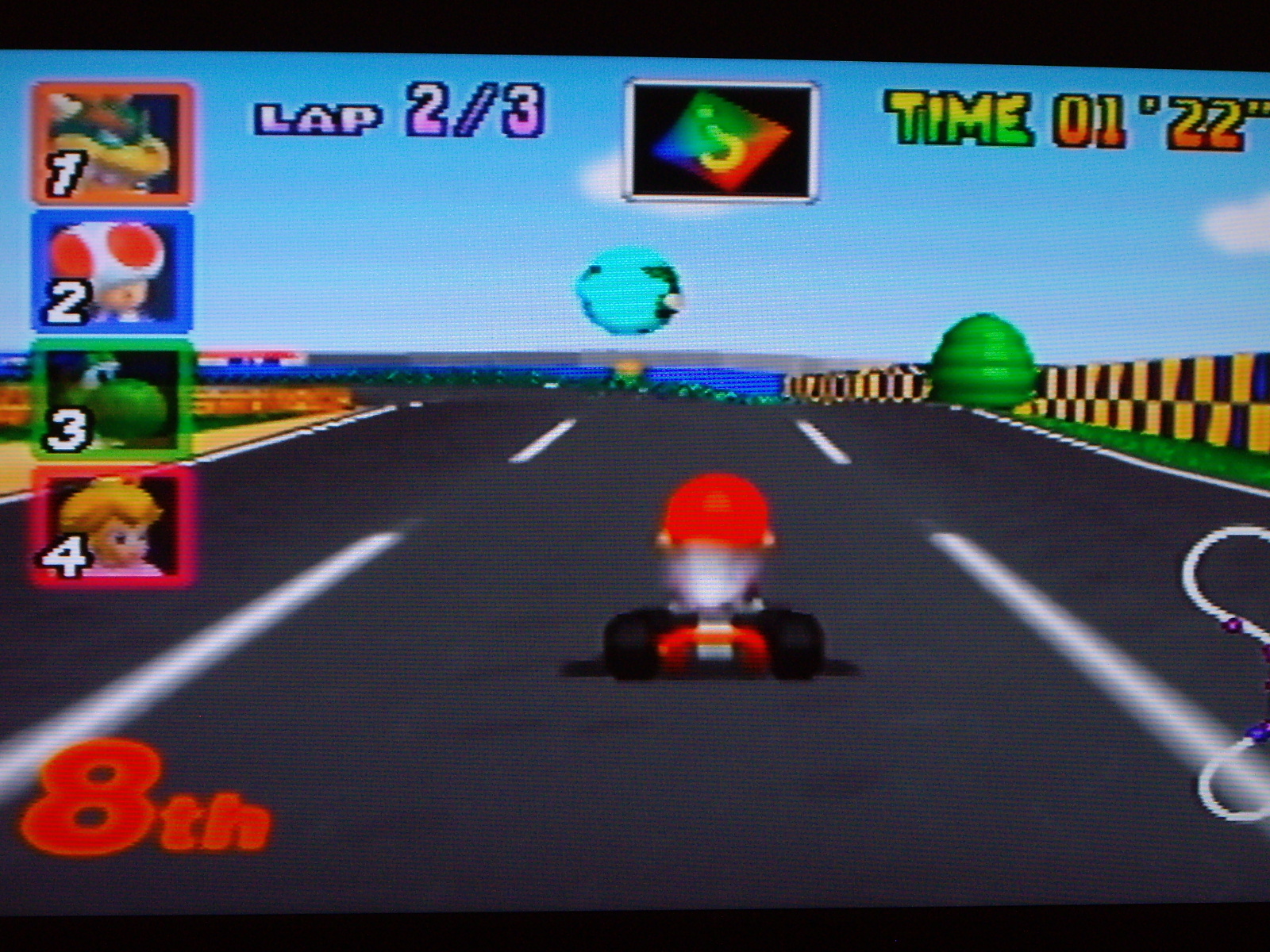
Les images suivantes ont été prises sans trépied avec mon appareil photo personnel. Les panoramas sont générés automatiquement. Pour le cas du panorama vertical, la transition entre les zones en chevauchement est encore selon une transition horizontale en raison de manque de temps. En raison du décors changeant dans le troisième panorama, les points d'intérêts ont été choisis manuellement.
Panorama 1

|

|

|

|

|

Panorama 2

|

|

|

|

|

Panorama 3
|
|
|
|
|
Crédits supplémentaires: Mélange et composition
Avec les techniques développées dans ces algorithmes, on arrive à créer des effets intéressants. On peut faire l'insertion d'images dans une autre image ou encore de mélanger deux images ensembles. On remarque un mauvais alignement pour le pont de l'image du Big Ben probablement dû au fait que les points ont été choisis principalement sur le bâtiment à l'arrière du pont.
|
Image séparée  |
Image séparée  |
Insertion d'image 
|
 |
 |

|
| |
 |

|
|
Image de base  |
Multiplication de l'image 
|
|
Image de base  |
Résultat 
|
|
Image de base  |
Résultat coupé 
|
|
Ville en été  |
Ville en hiver  |
Ville en transition 
|
Simon Fréchet
Université Laval, 2015