TP4: Assemblage de photos
GIF-7105 : Photographie algorithmique (Hiver 2015)
Par rapport à l'oeil humain, la plupart des caméras possèdent un champ de vue limité, ce qui réduit leurs capacités à photographier adéquatement des scènes au contenu largement étalé, telles que les paysages. Il est cependant facilement possible de prendre plusieurs photos successives sous différents angles. Dans ce travail, nous nous intéressons à l'assemblage et à la recomposition d'une série de photos en une seule image.
Une approche basique (avec appariement manuel) est d'abord présentée, suivie d'une approche plus complexe implémentant une technique d'appariement automatique. Des résultats sont fournis pour chacune de ces méthodes afin d'en apprécier l'efficacité.
Appariement manuel
Explications
Approche naïve (translation simple)
Une première approche naïve pour combiner plusieurs photographies pourrait être d'effectuer un simple "collage", c'est-à-dire d'aligner au mieux les deux images à l'aide d'une translation. Malheureusement, le résultat obtenu n'est pas à la hauteur des attentes, comme on peut le constater dans l'exemple suivant :



Dans cet exemple, les deux premières images ont été alignées de façon à ce que l'escalier au bas des deux images soit parfaitement superposé. Comme on peut le voir, le reste de l'image n'est pas du tout aligné. Pour permettre un bon alignement (autrement dit, passer du repère de la deuxième image à celui de la première), nous devons utiliser une transformation plus permissive qu'une simple translation. Cette transformation doit permettre la translation, la rotation et les changements de perspective : c'est une homographie.
Appariement manuel de points similaires
Afin de permettre l'estimation de l'homographie nécessaire pour le changement de repère, un certain nombre de points correspondant doivent être fournis à l'algorithme. Ces points sont choisis sur des objets facilement et uniquement identifiables dans les deux images. Dans un premier temps, nous fournissons à l'algorithme une suite de points manuellement appariés :

Calcul de la transformation
La transformation est caractérisée par une matrice 3x3, comportant donc 9 coefficients. Elle permet la transformation des points suivant l'équation suivante :
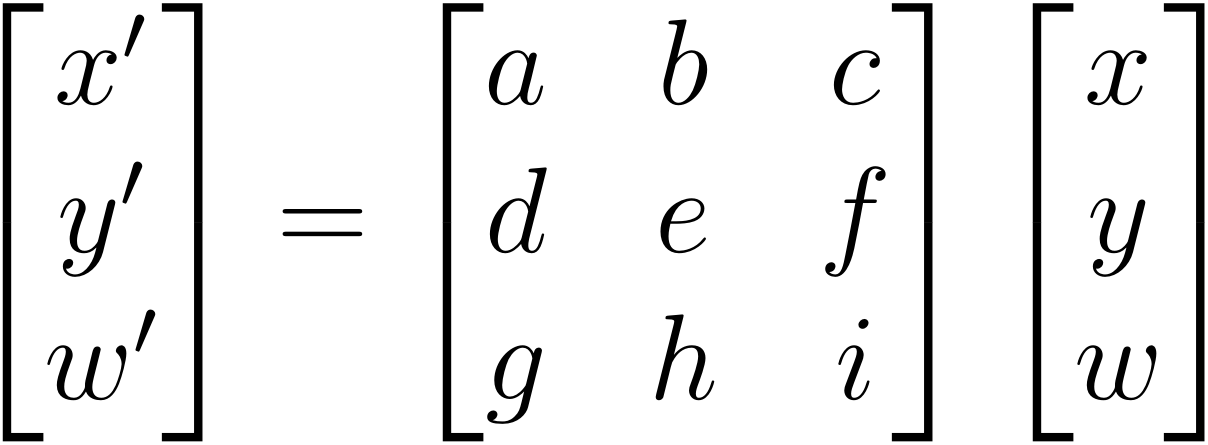
Nous cherchons donc à obtenir cette matrice de transformation, à partir d'un certain nombre de correspondances P -> P'. Une approche possible est de considérer le dernier coefficient comme un facteur d'échelle et à fixer arbitrairement sa valeur, ce qui, avec 4 paires de correspondances, nous permet d'obtenir un système d'équations à 8 équations (deux équations par point) et 8 inconnues, système qui est donc résolvable. Cependant, cette manière de procéder a l'inconvénient d'être très sensible au bruit, en particulier aux petites erreurs lors de la sélection des paires.
Afin d'améliorer la précision et la stabilité de l'appariement, nous utilisons plus de 4 points pour procéder au calcul de la transformation. Le calcul à proprement parler est effectué à l'aide de la décomposition en valeurs singulières du système d'équations suivant :
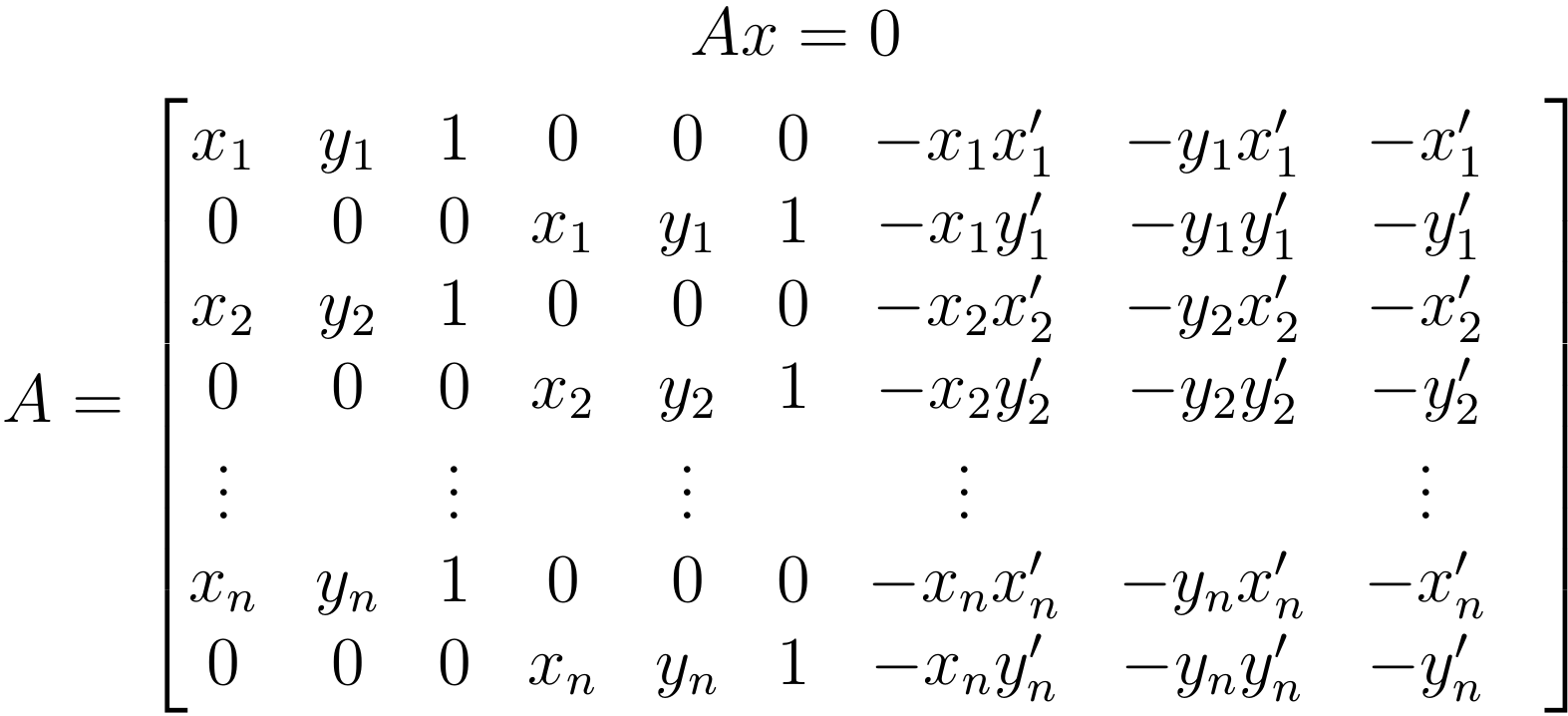
Dans le cas de ce TP, nous avons utilisé 16 paires de points par paire d'image afin d'assurer une bonne précision. La méthode présentée ici s'accomoderait évidemment de tout autre nombre de correspondances (en autant qu'il y en ait au moins quatre).
Les transformations obtenues peuvent être chaînées afin d'obtenir des transformations entre deux images pour lesquelles il n'existe pas de points de correspondance, par règle d'associativité :
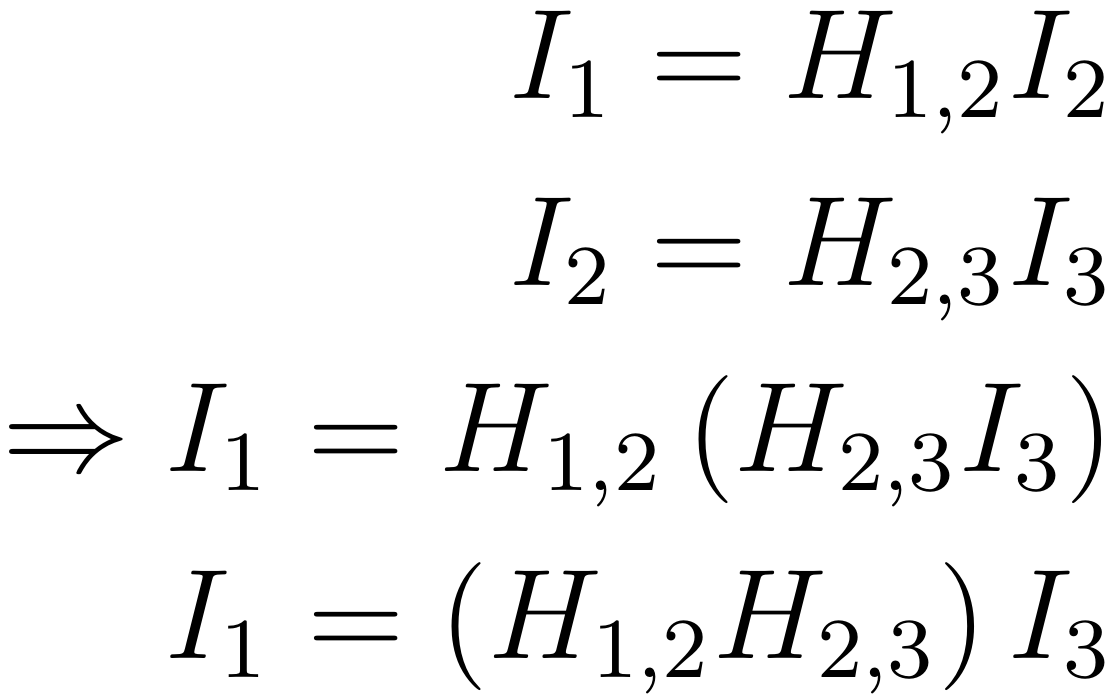
Par conséquent, la connaissance de deux liens de correspondance par image suffit et il n'est pas nécessaire de fournir des points appariant chaque image à toute les autres.
Transformation de l'image
Une fois l'homographie obtenue, l'image est déformée pour la placer dans le repère de la première image :

La forme trapéziodale est précisément due au changement de perspective. La valeur des pixels de l'image déformée est obtenue par une interpolation bilinéaire effectuée sur l'image originale.
Création de la mosaïque
Une fois les images projetées dans le même repère, elles peuvent être fusionnées afin de créer un panorama. Leur position dans l'image finale est indiquée par la translation implicitement calculée en obtenant l'homographie.

On remarque que les éléments présents sur les deux images sont maintenant alignés. Cependant, la couleur et la luminosité ne sont pas forcément exactement similaires sur les deux images (à cause d'une balance des blancs différente, d'un temps d'exposition plus court ou plus long, d'un léger changement dans l'illumination de la scène, etc.). Afin d'éviter la formation de frontières disgracieuses, une moyenne pondérée est effectuée dans la zone de transition, ce qui produit l'image finale suivante, qui pourrait être rognée afin d'éviter la présence de bandes noires :

Limitations
La technique utilisée ici suppose que toutes les images composant la mosaïque peuvent être projetées ans un même plan. Ce n'est pas forcément le cas dans la réalité : par exemple, deux images prises à des angles respectifs de 0 et 90 degrés possèdent des plans images orthogonaux, ce qui interdit toute reprojection. Même avec une différence d'angle plus faible (par exemple 75 degrés), le résultat peut se révéler assez disgracieux, comme sur l'image suivante :

L'homographie calculée est correcte : on peut d'ailleurs constater qu'il n'y a aucune frontière visible entre les images. Malgré tout, le résultat est mauvais, parce que les images formant les bords de la mosaïque sont très étirées par l'effet de perspective appliqué. Par exemple, l'image la plus à gauche passe d'une dimension de 1037x692 à une dimension de 4124x3450! En l'état, cette méthode ne fonctionne donc bien que sur des images entre lesquelles la différence angulaire est faible.
Résultats
Note importante
À cause de la limitation soulevée à la section précédente, reconstituer l'entièreté des panoramas n'était pas possible avec l'approche demandée. Ceux-ci ont donc été divisés en plusieurs sections. Les images sont cliquables pour obtenir des versions en plus haute résolution.
Panorama #1 (10 photos, 2 sections)


Panorama #2 (14 photos, 2 sections)


Panorama #3 (18 photos, 5 sections)





Analyse
La plupart des jeux d'images produisent de bons résultats. On remarque toutefois que, comme exposé précisément, la dimension angulaire horizontale du panorama est limitée : même la séparation en plusieurs mosaïques distinctes n'empêche pas certains effets indésirables. Ceux-ci sont particulièrement visibles dans les scènes incluant des personnes et des objets près du centre de projection des photos. Dans ces cas (par exemple la cafétéria), la déformation aux bordures gauche et droite du panorama sont particulièrement visibles. À l'opposé, dans les cas où les objets d'intérêt sont éloignés, comme dans la mosaïque du terrain du PEPS, la déformation est moins marquée et le résultat plus convaincant.
On remarque également que la présence d'objets se déplaçant (en particulier les personnes) dans les images produit des artefacts indésirables, puisqu'une même personne peut alors être présence à deux endroits différents dans la mosaïque, ou au contraire produire un effet "fantôme" dans les cas où la personne n'est présente que dans une seule des photos. Ce problème est particulièrement visible dans le panorama de la cafétéria : si la structure de la salle et les objets fixes sont bien rendus, les personnes sont souvent floues et mal définies. Il n'y a pas beaucoup de solutions à ce problème, si ce n'est prendre la séquence de photos plus rapidement.
Appariement automatique
Explications
L'appariement de points caractéristiques est une tâche fastidieuse à effectuer. Qui plus est, elle peut être source d'erreurs (il est facile d'apparier erronément deux points par inadvertance). Afin d'éviter à l'utilisateur cette étape, nous présentons ici une approche plus évoluée, capable de trouver elle-même les points correspondant dans une série d'image. La seule entrée nécessaire à cet algorithme est l'ordre des images tel qu'il doit être dans la mosaïque.
Détection de points d'intérêt
La première étape consiste à détecter, dans chaque image, les sections susceptibles de constituer de bons points de repère. Il existe beaucoup de critères pour optimiser cet objectif, mais tous partagent le même objectif : détecter les sections de l'image possédant une bonne variation et uniques dans leur voisinage. Dans notre cas, nous utilisons le détecteur de Harris, un détecteur de coins standard.
Le nombre de points trouvés est souvent trop élevé. En particulier, il arrive souvent que le détecteur extraie deux points très près l'un de l'autre (puisque si un pixel donné est au centre d'une zone d'intérêt, il y a de fortes chances pour que le pixel d'à côté le soit aussi). Par ailleurs, les points sont souvent mal répartis dans l'image, ce qui peut être problématique pour le calcul de l'homographie (plus les points sont rapprochés, plus l'erreur sur la position de ces points prend de l'importance dans la transformation obtenue). Pour ces raisons, nous utilisons une approche nommée ANMS (Adaptive Non-Maximal Suppression) tirée de [Brown, Szeliski et Winder, 2005], qui réduit le nombre de points en maximisant la distance entre ceux-ci.
Dans l'image présentée plus bas, les points détectés par Harris sont identifiés par un marqueur bleu, et les 40 points retenus par l'ANMS sont identifiés en rouge.

Extraction de descripteurs
Une fois les points d'intérêt détectés, un descripteur est extrait pour chacun de ceux-ci. Un descripteur est constitué d'un carré de 40x40 pixels autour du point d'intérêt et redimensionné en 8x8. Afin de rendre ces descripteurs plus robustes (et en particulier de les rendre plus invariant aux conditions d'éclairage), chaque descripteur est blanchi afin d'obtenir un vecteur de moyenne nulle et d'écart-type unitaire. Un exemple d'ensemble de descripteurs correspondant à l'image montrée plus haut est présenté à la figure suivante :

Appariement des descripteurs
Un ensemble de descripteurs ayant été extrait pour chaque image de la mosaïque, il nous faut maintenant en faire l'appariement, à savoir retrouver le descripteur correspondant à un autre dans une image différente. Pour ce faire, nous utilisons RANSAC afin de tester itérativement plusieurs appariements, desquels le meilleur est finalement conservé. À chaque itération, quatre descripteurs sont choisis au hasard et appariés à l'aide d'une différence au carré (le ratio entre le meilleur appariement et le second meilleur est également pris en compte). Une homographie est calculée à partir de ces correspondances. Cette homographie est par la suite testée sur les autres descripteurs : plus le nombre de descripteurs arrivant à une position proche de leur meilleur appariement est élevé, plus la transformation a de chances d'être correcte. Au final, la meilleure homographie est conservée, mais recalculée avec tous les points obtenant un bon appariement avec celle-ci. Dans notre cas, la distance seuil pour définir un "bon appariement" a été fixée à 5 pixels.
L'image suivante présente un exemple d'appariement entre deux photos successives. On remarque comment les points n'apparaissant que sur une seule photo sont systématiquement ignorés (ce qui est le comportement recherché) :

Génération de la mosaïque
Une fois les correspondances trouvées, l'approche peut se poursuivre de la même manière qu'avec la méthode manuelle (voir plus haut).
Résultats
Les résultats pour l'approche avec appariement automatique sont présentés plus bas. Les séquences d'images utilisées sont les mêmes que celles de la section précédente (appariement manuel).
Panorama #1 (10 photos, 2 sections)


Panorama #2 (14 photos, 2 sections)


Panorama #3 (18 photos, 5 sections)





Analyse
La plupart des résultats obtenus sont très bons, et se comparent favorablement à l'approche utilisant un appariement manuel. Les principaux problèmes sont rencontrés dans des scènes à faible contraste, avec peu de points de repère ou avec une différence angulaire importante entre les prises de vue, par exemple pour le panorama du grand axe. Dans ce cas, le nombre de correspondances trouvées n'est pas suffisant pour que RANSAC fonctionne correctement, d'où les erreurs obtenues, particulièrement aux figures 6D et 6E.
Notons cependant que les homographies retrouvées restent, jusqu'à un certain point, correctes. Par exemple, dans le cas de la figure 6E, l'estimation de l'homographie n'a pu se fier qu'à des points sur le pavillon à gauche de l'image, le reste étant de la neige sur laquelle aucune caractéristique particulière n'est présente. Par conséquent, une faible erreur sur cet objet lointain (le bâtiment reste correctement proportionné, avec à peine un peu de flou sur ses arêtes) entraîne une grande erreur lors de la projection de perspective.
Finalement, il faut préciser que l'on peut quelque peu palier ce problème en augmentant la tolérance sur les appariements. Par défaut, un appariement n'est considéré que si le ratio de la différence au carré de ses descripteurs et de la différence au carré du meilleur appariement suivant est inférieure à 0.6. Augmenter ce seuil, par exemple à 0.8, permet de générer plus de correspondances. Il est vrai que certaines de ces nouvelles correspondances seront mauvaises, mais RANSAC est capable de gérer ce genre de cas et de produire des résultats bien meilleurs (voir figure suivante). Dans tous les cas, il est clair que, pour RANSAC, il vaut mieux avoir beaucoup de correspondances dont certaines invalides que peu de correspondances mais aucune incorrecte.

Résultats supplémentaires
Deux autres séries de photographies ont été utilisées pour tester la méthode d'appariement automatique. La section qui suit présente les résultats obtenus.
Résultats
Panorama #4 (6 photos, 2 sections)


Panorama #5 (6 photos, 2 sections)


Analyse
Les résultats obtenus (rappelons que ces panoramas ont été générés automatiquement) sont globalement bons. On constate un peu de flou sur les zones proches de l'appareil photo, comme sur le lampadaire de la première série de photos, mais l'alignement général est très bon. Notons que ces panoramas ont été générés avec 3 photos, l'axe optique de chaque photo étant à 22.5 degrés de la précédente. Sachant que la focale équivalente 35 mm de cet appareil est de 24 mm, et donc que son angle de champ est d'environ 72 degrés, on peut en déduire que le panorama couvre près de 140 degrés d'angle de champ, ce qui est déjà fort acceptable. Il aurait été possible d'ajouter une quatrième photo à ces mosaïques, mais pas sans créer d'effets indésirables dus à la perspective dont nous avons déjà parlé. L'image suivante montre un exemple d'un tel appariement.

Crédits supplémentaires
Détection automatique de panorama
Un algorithme a également été pensé afin de détecter automatiquement un panorama dans une suite d'image. Cet algorithme se base sur la reconnaissance de caractéristiques, associé à un seuil afin de déterminer si deux images sont suffisamment semblables pour faire partie de la même scène. Dans ce cas, ces images sont passées à la procédure d'appariement automatique vue plus haut, afin de réaliser le panorama.
Par exemple, en utilisant un dossier d'entrée contenant les photos suivantes :







L'algorithme recompose le panorama suivant :
