Miniprojet : Moyennage des positions des caméras.¶
Avec l'arrivée de la caméra de type GoPro sur le marché, beaucoup de vidéos sont réalisés à l'aide de ce type d'appareil, notamment lors d'activité sportive. Or, comme il est fréquent que les caméras soient montées sur le casque des vidéastes amateurs, il s'ensuit que la séquence vidéo produite est rarement stable. Afin de palier à ce problème et de rendre le visionnement de ces vidéos moins nauséeux, un algorithme de stabilisation en tirant profit d'outil déjà existants.
Le but de ce projet est de produire un algorithme de stabilisation de l'image applicable sur une séquence vidéo afin d'obtenir une séquence où les mouvements sont plus fluides et moins étourdissants. L'idée derrière l'algorithme implanté est en partie tirée du projet Hyperlapse de Microsoft.
Cette section présente les étapes à suivre pour appliquer la stabilisation des images d'un vidéo.
a) Prise de vidéos et calibration¶
Afin d'optimiser la reconstruction d'une scène à partir d'une séquence vidéo, il est nécessaire d'obtenir les paramètres de calibration de la caméra utilisée. Il existe différents outils pour obtenir cette calibration. Dans ce projet, la librairie de code OpenCV a été utilisée avec ses extensions en Python. Les paramètres de calibration extraits sont nécessaires pour notamment corriger la distortion radiale très importante dans les caméras dites à grand angle (comme la GoPro).

Figure - Example d'une cible de calibration.
Les paramètres de calibration récupérés prennent la forme de deux matrices. \[
Calibration =\begin{bmatrix}
fx & 0 & cx \\[0.3em]
0 & fy & cy \\[0.3em]
0 & 0 & 1
\end{bmatrix}
\] \[
DistortionRadiale = \begin{bmatrix}k1 & k2 & p1 & p2 & k3\end{bmatrix}
\]
Pour plus de détails sur la signification de chacun de ces coefficients, le lecteur est référé à la page d'OpenCV traitant du sujet.
b) Échantillonnage du vidéo¶
À l'aide de la librairie Python appelée MoviePy, il a été possible d'écrire une application qui extrait de automatiquement toutes les images d'un vidéo en échantillonnant un nombre arbitraire d'images par seconde (FPS).





Figure - Example de 5 images extraites d'un vidéos à une fréquence de 30 FPS avec correction radiale.
Durant cette phase, à chaque image extraite, un algorithme de correction est appliqué pour corriger la déformation radiale en fonction des paramètres de calibration obtenus à l'étape précédente. L'algorithme de correction appliquée provient de la librairie OpenCV et prend directement en entrée les matrices de calibration mentionnée ci-haut.


Figure - À gauche : Image originale. À droite : Correction à l'aide d'OpenCV.
Une implémentation manuelle de cette algorithme qui ne nécessite que scikit-image et aucune compilation complexe est
aussi possible. Ce code fonctionne en permettant la sélection de plusieurs ensembles de 3 points que l'utilisateur doit aligné sur des lignes qui devraient être droites dans l'image. À partir de cette sélection, l'algorithme identifie les paramètres de distortion et corrige l'image. En modifiant ce code pour qu'il affiche à la console les paramètres de distortion estimés, il est possible, sans cible de calibration, d'obtenir un résultat utilisable.

Figure - Sélection des points avec le code exemple utilisant Scikit-Image.

Figure - Correction appliquée.
c) Reconstruction tri-dimensionnelle¶
Afin de déterminer la position et l'orientation de chacune des images prélevées du vidéos, il est nécessaire d'effectuer une reconstruction tri-dimensionnelle de la scène. Pour ce faire, l'outil
VisualSFM de Changchang Wu est utilisé. Cet outil offre des algorithmes de reconstruction d'une scène 3D à partir d'une série de prises de vue de la même scène. Il est donc possible d'utiliser VisualSFM pour analyser des images séquentielles extraites d'un vidéo.
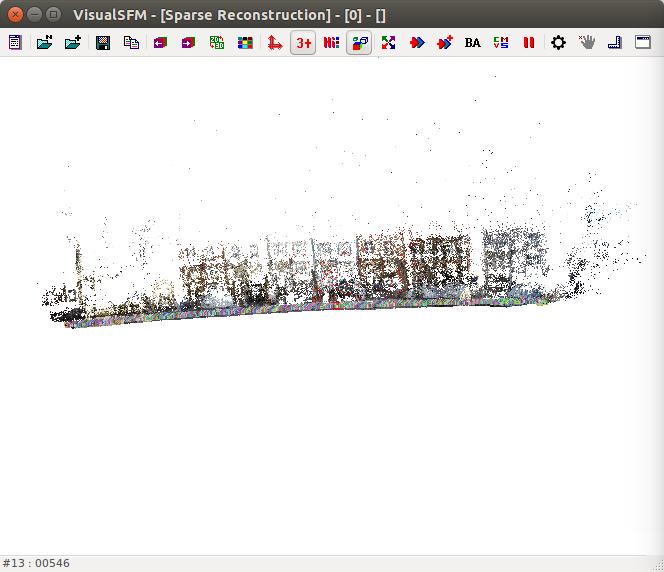
Figure - VisualSFM.
Pour faire le rendu d'une scène à partir d'un vidéo, il faut employer des configurations approriées. Tout d'abord, afin d'optimiser la performance de l'outil, il est préférable d'avoir au préalable corriger la distortion radiale de la lentille (tel qu'expliqué à l'étape précédente). En effet, bien que VisualSFM peut appliquer une correction en cours de traitement, les résultats ne sont pas toujours bons, surtout lorsqu'il y a une distortion radiale prononcée. Cette distortion peut avoir pour effet de fausser la reconstruction de l'environnement. Ensuite, si le poste de travail utilisé possède une carte graphique (GPU) Nvidia compatible avec la technologie CUDA et que le tout est correctement configuré, il peut être plus performant d'indiquer à VisualSFM d'utiliser le GPU comme unité de traitement. Pour ce faire on sélectionne l'option correspondante tel qu'illustré à la figure suivante.
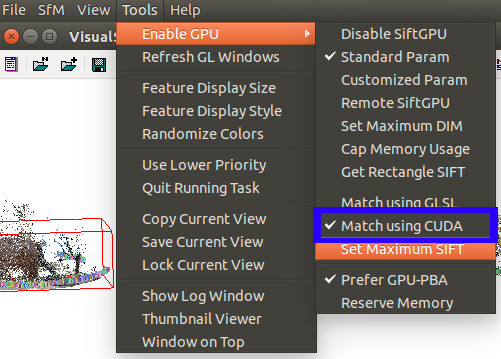
Figure - Sélection du GPU comme unité de calculs.
Afin de lancer l'analyse, il faut d'abord charger les images de la scène. Une fois le chargement complété (le temps d'ouverture varie en fonction du nombre d'images et du système), l'algorithme d'identification de points d'intérêt peut être lancé. Il existe plusieurs techniques différentes disponibles dans VisualSFM pour effectuer cette phase.
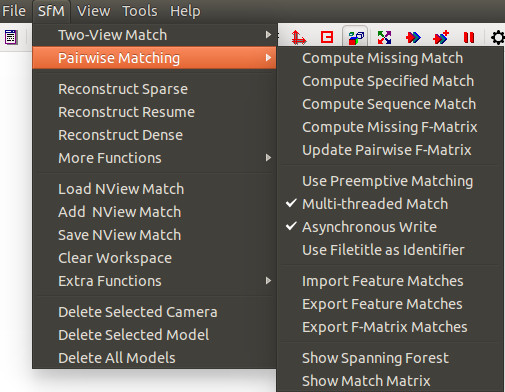
Figure - Options d'appariement.
Le premier choix,
Compute Missing Match, tente d'apparier toutes les images entre elles. Le troisième
Compute Sequence Match permet d'effectuer un appariement entre l'image et un nombre arbitraire d'images la précédente et la suivante dans la séquence chargée. Cette option permet grandement de réduire le temps de calcul puisque chaque image est appariée à un sous-ensemble uniquement et non pas à l'entièreté de l'échantillon. Par essais et erreurs, il a été déterminé qu'il est généralement bon de fixer la fenêtre à
\(2~sec*FPS_{video}\). Une fois la quantité d'image fixée, la génération est lancée. Cette étape peut être considérablement longue dépendamment du nombre d'images, de la taille de la fenêtre et si une carte graphique est disponible.
Une fois la génération complétée, il est fortement recommandé de fixer les paramètres de calibration de la caméra afin que VisualSFM puisse correctement estimer la représentation 3D de la scène, faute de quoi les résultats pourraient être imprévisibles. De plus, il est recommandé de désactiver la distortion radiale (en décochant dans le même menu
Use Radial Distortion). Il est inutile que VisualSFM tente de la corriger puisque les images ont été corrigées.
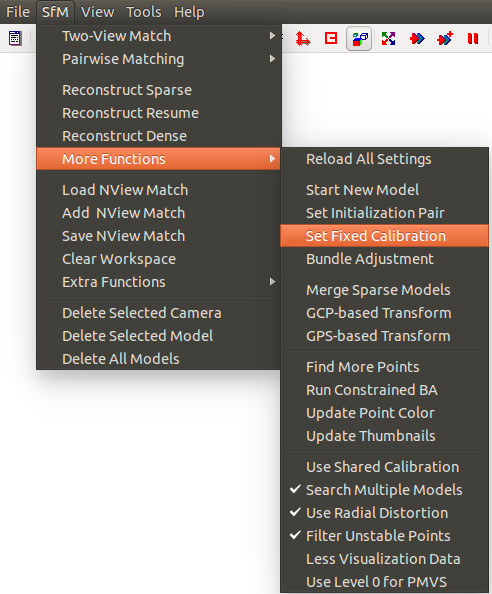
Figure - Calibration de la caméra.
Dans la boîte de dialogue qui s'ouvre, il faut saisir
\(fx,fy,cx,cy\) tels qu'identifiés précédemment dans la phase de calibration. Le paramètre
\(r\) est optionnel et n'est pas spécifié dans le cas présent.
Une fois toutes ces options sélectionnées on peut lancer l'appariement en sélectionnant
SfM -> Reconstruct Sparse. La génération tridimensionnel sera lancée et à la toute fin, un nuage de points avec les caméras s'affichera dans VisualSFM.

Figure - Résultat d'une reconstruction.
Pour le projet, il n'est pas nécessaire d'effectuer une reconstruction dite "dense", opération qui consiste à densifier le nuage de points pour retrouver plus de surfaces de la scène. Toutefois, si l'utilisateur désire générer cet algorithme, il est accessible dans le menu
SfM -> Reconstruct Dense. Un résultat exemple de ce type de reconstruction est illustré à la figure suivante.

Figure - Résultat d'une reconstruction.
Finalement, afin d'obtenir un fichier contenant les caméras, le résultat doit être sauvegardé en allant dans le menu SfM -> Save NView Match. Ce fichier sera utilisé pour exécuter l'algorithme de stabilisation.
d) Algorithme de stabilisation¶
Le programme implémente un algorithme de stabilisation des rotations et des positions des caméras dans la scène. Pour effectuer cette stabilisation de l'image, il faut tout d'abord charger les propriétés des caméras de la scène à l'aide du fichier NVM précédemment généré. Le détail de ce fichier est expliqué sur le site de VisualSFM. Pour résumé l'essentiel, chaque caméra est enregistrée avec sa translation et sa rotation par rapport au plan monde. Tel qu'expliqué sur le site du concepteur, les rotations sont enregistrées sous formes de quaternions et la combinaison de rotation et translation à appliquer pour arriver à la position réelle de la caméra dans le repère monde s'exprime comme suit :
\[
C =-R'T
\] Une fois chaque caméra extraite (
\(Cam_{r}\)) avec ses propriétés, leur position et leur rotation sont normalisées à l'aide d'un filtre Gaussien appliqué sur les caméras précédentes et suivantes avec une taille de fenêtre pouvant être arbitrairement fixée au besoin. Les nouvelles valeurs de rotation et de translation extraites permettent d'obtenir une caméra virtuelle
\(Cam_{v}\) qui, théoriquement, est à une nouvelle position qui est plus près de la position de la caméra précédente et celle qui la suit. Finalement, pour reconstituer l'image du vidéo stabilisé, on place
\(Cam_{v}\) à l'origine et on applique la même transformation sur
\(Cam_{r}\). Comme
\(Cam_{v}\) est à l'origine, on observe que les coordonnées de son plan image sont :
\[
Coin_{HG} = (-w/2;-h/2;f)
Coin_{HD} = (w/2,-h/2,f)
Coin_{BG} = (-w/2,h/2,f)
Coin_{BD} = (w/2,h/2,f)
\] Où f est la focal de la caméra, w la largeur de l'image et h la hauteur de l'image. Il est à noter que la référence utilisée par VisualSFM pour les coordonnées des caméras place l'axe des X positifs vers la droite, l'axe des Y positifs vers le bas et l'axe des Z positif vers le plan de l'image.
Pour ce qui est des coordonnées du plan image de
\(Cam_{r}\), on applique la même transformation requise pour mettre
\(Cam_{v}\) à l'origine sur les coordonnées du plan image de
\(Cam_{r}\).
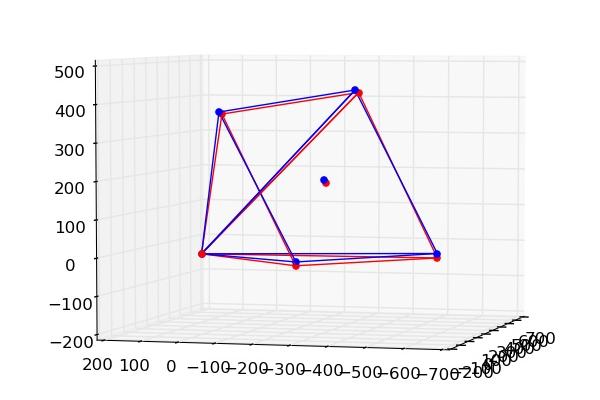
Figure - Caméras avec positions brutes. En rouge : Réel, En bleu : Virtuelle.
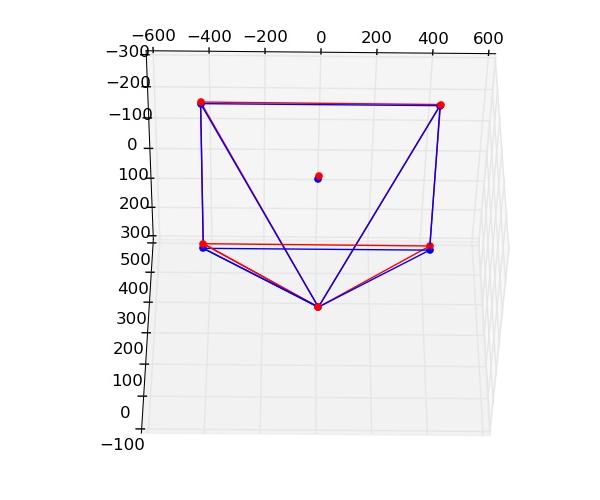
Figure - Transformation pour ramener \(Cam_{v}\) à l'origine appliquée aux deux caméras. En rouge : Réel, En bleu : Virtuelle.
Finalement, afin d'obtenir la scène tel que vue par
\(Cam_{v}\), il faut projeter le plan image de
\(Cam_{r}\) (et donc la photo qui lui correspond) sur celui de
\(Cam_{v}\). Pour ce faire, la propriété suivante des triangles rectangles a été employée.
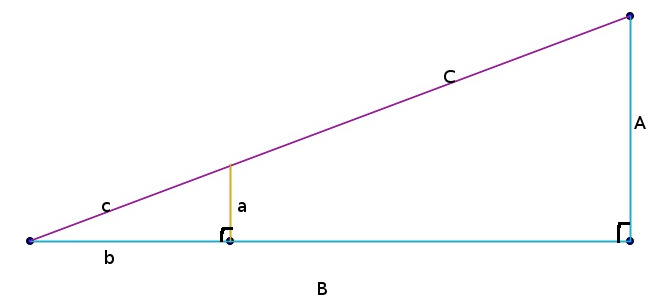
Figure - Proportionnalité.
Dans ce triangle,
\[
\frac{a}{A}=\frac{b}{B}=\frac{c}{C}
\]
En projetant dans le plan des XZ, on obtient que
\[
x_{r}/x_{r'}=z_{r}/z_{r'}
\]
Où \(x_{r}\) et \(z_{r}\) sont les coordonnées des coins du plan image de \(Cam_{r}\) après avoir subi la transformation nécessaire pour ramener \(Cam_{v}\) à l'origine. \(x_{r'}\) et \(z_{r'}\) sont les coordonnées du plan \(Cam_{r}\) après avoir été projetées sur le plan image de \(Cam_{v}\). Or, comme \(z_{r'}=focale\) et que l'on cherche \(x_{r'}\), on obtient:
\[
x_{r'}=x_{r}/z_{r}*f
\]
Le même rationnel est appliqué pour obtenir la projection du plan image dans YZ.
Finalement, on délaisse la dimension Z et les photos obtenus sont assemblées en un vidéo à l'aide de la librairie MoviePy.
a) Prises de vidéo et calibration¶
Pour ce projet, tous les vidéos ont été produit à l'aide d'une caméra GoPro. Dans le cas des vidéos de bicycle, une GoPro 2 a été utilisée. Pour le vidéo d'escalade, la caméra employée est une GoPro selon la description sur le site, mais malheureusement, aucun détail quant au modèle n'est spécifié. La calibration appliquée a toutefois été la même que celle obtenue pour GoPro 2 avec le réglage Wide. Les matrices de calibration et de distortion radiale sont données ci-dessous.
\[
Calibration =\begin{bmatrix}
2032.38095 & 0 & 735.711801 \\[0.3em]
0 & 2013.69043 & 594.422808 \\[0.3em]
0 & 0 & 1
\end{bmatrix}
\] \[
DistortionRadiale = \begin{bmatrix}-.29490627657552443 & .18468813426740099 & .0059061328069191458 & -.0053931865111826963 & -.091543394986439708\end{bmatrix}
\]
b) Échantillonnage du vidéo¶
Les vidéos échantillonnés sont les suivants (après correction pour la distortion radiale):
Vidéo - Vidéo d'escalade. Remerciement à Shane Van Oostendorp pour l'originale.
Vidéo - Balade en Vélo. Remerciement à Marc-André Gardner.
Vidéo - Longue balade en Vélo. Remerciement à Marc-André Gardner.
À noter, le vidéo de la courte balade à vélo en version originale non-compressée peut être téléchargé ici. Afin d'éviter les fichiers trop volumineux, seul ce vidéo a été téléversé.
c) Reconstruction tri-dimensionnelle¶
d) Stabilisation et rendu final¶
Les résultats finaux pour les trois vidéos précédents après avoir appliqué l'algorithme de stabilisation sont présentés ci-dessous.
Vidéo - Stabilisation du vidéo d'escalade.
Vidéo - Stabilisation du vidéo de la balade en vélo.
Vidéo - Stabilisation du vidéo de la longue balade en vélo.
Les résultats obtenus présentent certaines caractéristiques intéressantes. Tout d'abord, on peut remarquer, surtout dans le vidéo de l'escalade, que la normalisation des positions et des rotations a eu pour effet d'atténuer certaines variations. Toutefois, il est possible de constater que dans certains cas, le mouvement induit par le cadrage du vidéo, qui se déplace dû à l'effet de projection, peut donner l'impression que le vidéo est encore plus instable. Une autre limitation de ce projet est que la qualité du rendu finale repose entièrement sur l'efficacité de VisualSFM à placer les caméras dans l'espace avec la bonne orientation et la bonne position. Or, il est fréquent que le flou du mouvement de la caméra provoque des incertitudes qui entraîne le placement erroné des caméras. Ainsi, lors de la normalisation, il peut arriver que certaines caméras soient influencées par ces données problématiques. Il aurait pu être intéressant d'améliorer le résultat en combinant l'information de plusieurs caméras dans une même scène afin de combler les bandes noires lorsqu'elles s'affichent sur les bords. Bien que cette implémentation ait été testée, les résultats qui en ressortent restent mitigés.
Vidéo - Complétion des côtés de l'image à l'aide des caméras précédente et suivante.
Une amélioration possible aurait été l'applicationm de l'algorithme de découpage qui identifie la ligne de pixel de moindre coût entre deux images afin d'en effectuer la fusion (tel que vu au TP2 sur les textures). De cette façon, le fondu entre les bordures pourrait être plus invisible.
Bien que théoriquement valable, l'algorithme suggérée repose sur une prise de données impeccable pour fonctionner correctement. De plus, l'identification des points d'intérêt aurait pu être facilitée par la capture d'un vidéo où la caméra est dirigée vers la trajectoire du caméraman. De cette façon, les points d'intérêt situés à l'horizon auraient pu faciliter la récupération du tracking après un moment d'instabilité. Il serait intéressant d'explorer davantage cette avenue dans le futur.

